Sumber daya
Atribut LLM yang Harus Dipantau oleh Setiap CISO Saat Ini
Oleh Sarang Warudkar - Senior Technical PMM (CASB & AI)
18 Februari 2026 5 Membutuhkan waktu 5 menit untuk dibaca

Alat kecerdasan buatan (AI) kini memengaruhi pekerjaan sehari-hari di berbagai bidang, termasuk penulisan, analisis, otomatisasi rapat, dan pengembangan perangkat lunak. Adopsi yang cepat ini membawa peningkatan produktivitas yang signifikan, namun juga memperkenalkan permukaan keamanan baru yang dipicu oleh perilaku model bahasa besar (LLMs). Pemeriksaan SaaS tradisional tidak lagi memadai. Para CISO kini mengevaluasi aplikasi dan model di baliknya dengan perhatian yang sama.
Blog ini menjelaskan atribut LLM yang memengaruhi risiko perusahaan dan langkah-langkah praktis yang dapat digunakan oleh pemimpin keamanan untuk mengelolanya.
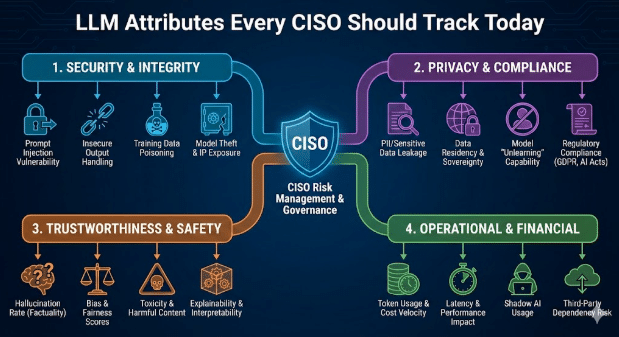
Mengapa Atribut LLM Penting
Sebagian besar produk AI SaaS mengintegrasikan model bahasa besar (LLM) pihak ketiga. Hal ini menciptakan ketergantungan ganda. Meskipun aplikasi mungkin lulus semua pemeriksaan keamanan, model di bawahnya tetap dapat mengekspos data, menghasilkan kode yang tidak aman, atau bocornya alur kerja sensitif. Pemahaman yang jelas tentang lapisan LLM menutup celah ini dan menyelaraskan tata kelola AI dengan ancaman modern.
1. Risiko AI pada Tingkat Aplikasi: Landasan
Sebelum menganalisis model, pastikan bahwa aplikasi AI SaaS memenuhi persyaratan inti yang diharapkan dalam lingkungan perusahaan.
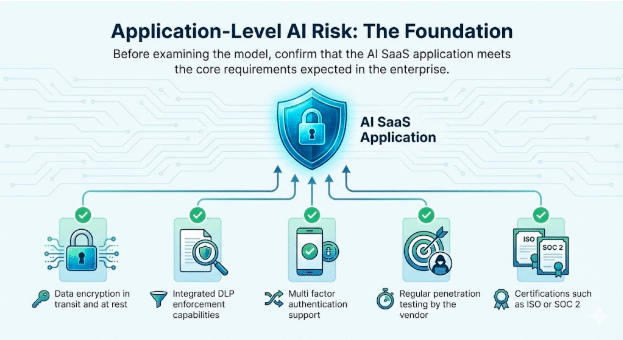
Atribut dasar untuk diverifikasi
- Enkripsi data selama transmisi dan saat disimpan
- Kemampuan penegakan DLP terintegrasi
- Dukungan otentikasi multi faktor
- Pengujian penetrasi rutin oleh penyedia layanan
- Sertifikasi seperti ISO atau SOC 2
Pemeriksaan ini tetap sangat penting. Mereka membangun kepercayaan terhadap layanan itu sendiri dan menjadi landasan untuk peluncuran AI yang aman.
2. Perilaku LLM: Sumber Permukaan Risiko Baru
Atribut LLM secara langsung memengaruhi cara aplikasi merespons pengguna nyata dan prompt adversarial. CISOs kini memantau perilaku berikut ini pada setiap model tertanam.
Integrasi GenAI dan LLM
Identifikasi model yang tepat, wilayah hosting, pola pembaruan, dan apakah penyedia layanan melakukan penyesuaian menggunakan data pelanggan.
Paparan Jailbreak
Jailbreak terjadi ketika pengguna memanipulasi prompt untuk melewati kontrol keamanan LLM. Teknik umum meliputi peran ganda, instruksi berlapis, bingkai fiksi, dan bahasa tidak langsung atau terenkripsi. Karena interaksi ini mirip dengan penggunaan normal, mereka seringkali lolos dari kontrol dasar. Memantau upaya jailbreak membantu tim keamanan mendeteksi penyalahgunaan secara dini, memperkuat batasan keamanan, dan menunjukkan tata kelola proaktif selama audit.
Contoh
- Seorang penyerang meyakinkan chatbot untuk menjelaskan cara menonaktifkan MFA pada akun pelanggan. Hal ini membuka akses langsung ke data sensitif dan melanggar tata kelola identitas dalam alur kerja yang tampak sah.
Pembuatan Malware dan Kode Berbahaya
LLMs terkadang menghasilkan kode yang menyertakan jalur eksekusi tersembunyi atau rutinitas eksfiltrasi.
Contoh
- Seorang insinyur menyalin kode yang disarankan oleh AI ke dalam layanan internal. Kode tersebut mengandung kebocoran data tersembunyi. Hal ini memicu pelanggaran yang tidak terdeteksi karena logika kode tersebut tampak valid.
Toksisitas, Bias, dan Risiko Output CBRN
Model dapat menghasilkan teks yang tidak aman saat diberikan prompt yang sensitif atau bersifat adversarial. Pantau perilaku ini untuk unit bisnis di mana keamanan, kepatuhan, atau risiko fisik menjadi pertimbangan.
Contoh
- Toksisitas: Sebuah chatbot dukungan internal merespons keluhan pelanggan yang ditingkatkan dengan bahasa yang kasar atau mengancam setelah diberi perintah yang bersifat agresif, yang dapat menimbulkan risiko bagi departemen SDM dan merek ketika transkrip percakapan tersebut direkam atau dibagikan.
- Bias: Tim perekrutan menggunakan model bahasa besar (LLM) untuk menilai calon karyawan, dan model tersebut secara konsisten menurunkan peringkat profil yang mengandung indikator gender atau kasta, sehingga mengekspos organisasi pada risiko diskriminasi dan temuan audit.
- Risiko Output CBRN: Seorang pengguna R&D menanyakan kepada model bahasa besar (LLM) tentang cara meningkatkan proses kimia, dan model tersebut memberikan panduan langkah demi langkah yang sesuai dengan sintesis kimia yang dibatasi, sehingga menimbulkan risiko paparan keamanan regulasi dan fisik.
Keselarasan dengan Panduan NIST dan OWASP untuk Model Bahasa Besar (LLM)
NIST telah merilis Profil Kecerdasan Buatan Generatif (Generative AI Profile) yang dengan cepat menjadi acuan standar untuk manajemen risiko kecerdasan buatan yang bertanggung jawab. Tim keamanan dan kepatuhan kini mengharapkan setiap aplikasi berbasis LLM (Large Language Model) untuk secara jelas memenuhi harapan-harapan ini.
Perusahaan-perusahaan mengajukan pertanyaan langsung.
- Siapa yang bertanggung jawab atas cara penggunaan AI dan atas hasilnya?
- Kasus penggunaan LLM mana yang secara eksplisit diizinkan atau dilarang?
- Apakah data pelatihan dan penyempurnaan dinyatakan secara transparan?
- Bagaimana risiko seperti injeksi mendadak, halusinasi, dan akses data tanpa izin ditangani
Ketika pertanyaan-pertanyaan ini tidak memiliki jawaban yang jelas, risiko audit meningkat secara signifikan. Di sektor-sektor yang diatur seperti layanan kesehatan dan jasa keuangan, ketidakselarasan dengan pedoman NIST meningkatkan kemungkinan kebocoran data, sanksi regulasi, dan kegagalan audit.
Secara paralel, OWASP Top 10 untuk Aplikasi LLM mendokumentasikan kelas baru kerentanan yang melampaui masalah keamanan aplikasi tradisional. Kerentanan ini meliputi injeksi prompt, penanganan output yang tidak aman, pencemaran data pelatihan, dan integrasi yang tidak aman.
Insiden nyata sudah mencerminkan risiko-risiko ini. Dalam satu kasus, aplikasi SaaS memungkinkan pengguna mengunggah dokumen untuk diproses oleh AI. Seorang penyerang menyisipkan instruksi tersembunyi di dalam file, model AI mengeksekusinya, dan data sensitif perusahaan terungkap. Skenario-skenario ini terjadi di lingkungan produksi yang aktif, dan organisasi yang tidak secara aktif memantau dan mengatasi risiko-risiko ini menghadapi risiko keamanan yang signifikan.
Contoh
- Sebuah model tanpa validasi output dapat bocorkan kunci admin selama upaya injeksi prompt. Hal ini menyebabkan kerentanan sistem secara keseluruhan meskipun terdapat kontrol aplikasi yang kuat.
Bagaimana CISOs Mengubah Atribut Ini Menjadi Tindakan
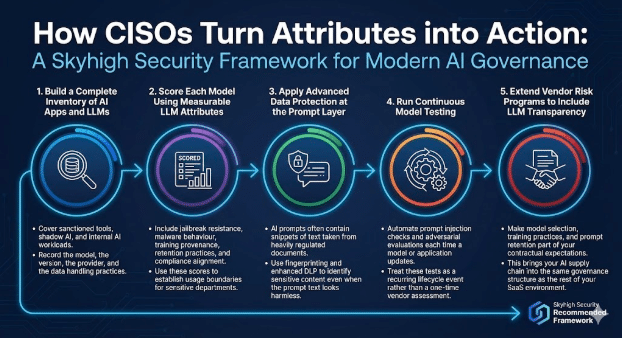
Program tata kelola AI modern menggabungkan pemeriksaan aplikasi dengan kontrol yang sadar model.
Skyhigh Security kerangka kerja berikut.
1. Buat Daftar Lengkap Aplikasi Kecerdasan Buatan (AI) dan Model Bahasa Besar (LLMs)
Mencakup alat yang disetujui, AI bayangan, dan beban kerja AI internal.
Catat model, versi, penyedia, dan praktik penanganan data.
2. Memberikan Skor pada Setiap Model Menggunakan Atribut LLM yang Dapat Diukur
Termasuk ketahanan terhadap jailbreak, perilaku malware, asal-usul pelatihan, praktik penyimpanan, dan kesesuaian dengan kepatuhan. Gunakan skor-skor ini untuk menetapkan batasan penggunaan untuk departemen-departemen sensitif.
3. Terapkan Perlindungan Data Lanjutan pada Lapisan Prompt
Prompt AI sering kali mengandung potongan teks yang diambil dari dokumen yang sangat diatur. Gunakan fingerprinting dan DLP yang ditingkatkan untuk mengidentifikasi konten sensitif bahkan ketika teks prompt terlihat tidak berbahaya.
4. Lakukan Pengujian Model Berkelanjutan
Otomatiskan pemeriksaan injeksi prompt dan evaluasi adversarial setiap kali model atau aplikasi diperbarui. Anggaplah tes-tes ini sebagai peristiwa siklus hidup yang berulang daripada penilaian vendor sekali saja.
5. Perluas Program Manajemen Risiko Vendor untuk Mencakup Transparansi LLM
Jadikan pemilihan model, praktik pelatihan, dan retensi prompt sebagai bagian dari harapan kontrak Anda. Hal ini akan mengintegrasikan rantai pasok AI Anda ke dalam struktur tata kelola yang sama dengan lingkungan SaaS Anda yang lain.
Jalan di Depan
LLMs mengubah cara perusahaan menggunakan AI, dan mereka juga mengubah cara CISOs mengevaluasi risiko.
Dalam tata kelola aplikasi tradisional, tim keamanan memisahkan dua aspek. Aplikasi harus memenuhi standar perusahaan dalam hal kontrol akses, perlindungan data, pencatatan, dan kepatuhan. Secara terpisah, platform dasar harus memenuhi harapan dalam hal keandalan, keamanan, dan operasional.
LLMs memperkenalkan tanggung jawab dua lapis yang sama, dengan konsekuensi yang lebih besar.
- Pada lapisan aplikasi, organisasi harus mengatur cara fitur kecerdasan buatan (AI) diakses oleh pengguna. Hal ini mencakup siapa yang dapat mengakses fitur tersebut, data apa yang dapat dikirimkan, bagaimana hasil keluaran dibagikan, dan bagaimana aktivitas dicatat untuk audit dan penyelidikan. Kontrol-kontrol ini mencerminkan praktik keamanan aplikasi yang sudah dikenal, yang diperluas ke dalam alur kerja yang didorong oleh AI.
- Pada tingkat model, CISOs harus mengevaluasi bagaimana LLM berperilaku dalam kondisi dunia nyata. Hal ini mencakup cara model menangani prompt sensitif, apakah model menghasilkan output yang tidak aman atau bias, cara model menyimpan atau menggunakan kembali data, serta seberapa tangguh model terhadap penyalahgunaan seperti prompt injection atau data poisoning. Perilaku-perilaku ini berada di luar pengujian aplikasi tradisional dan memerlukan tata kelola yang eksplisit.
Pemantauan atribut LLM seperti penggunaan data, perilaku keamanan, cakupan batasan keamanan, dan pola kegagalan memberikan keyakinan yang sama kepada pemimpin keamanan seperti yang mereka harapkan dari program aplikasi yang matang. Dengan visibilitas ini, CISOs dapat mendukung adopsi AI yang lebih luas sambil tetap menjaga keamanan, privasi, dan komitmen regulasi di seluruh organisasi.
Tentang Penulis

Sarang Warudkar
Manajer Pemasaran Teknis Senior
Sarang Warudkar adalah Manajer Pemasaran Produk berpengalaman dengan lebih dari 10 tahun di bidang keamanan siber, yang terampil dalam menyelaraskan inovasi teknis dengan kebutuhan pasar. Dia memiliki keahlian mendalam dalam solusi seperti CASB, DLP, dan deteksi ancaman berbasis AI, yang mendorong strategi masuk ke pasar dan keterlibatan pelanggan yang berdampak besar. Sarang memiliki gelar MBA dari IIM Bangalore dan gelar insinyur dari Universitas Pune, yang menggabungkan wawasan teknis dan strategis.
Konten Terkait



Blog yang sedang tren
Skyhigh Security Achieves CSA STAR Level 2 Certification, Raising the Bar for Independent Cloud Security Assurance
Stuart Bayliss and Sarang Warudkar June 25, 2026
A Different Approach: Why the Answer to Browser Security Is Not a New Browser
Sarang Warudkar June 17, 2026
Skyhigh Security Penilaian IRAP pada Tingkat PROTECTED untuk Tahun 2026
Sarang Warudkar dan Stuart Bayliss 21 Mei 2026
AI Tools Created a Security Gap Your Network Cannot See. Browser Controls Close it.
Sarang Warudkar 19 Mei 2026
Mengatasi Fragmentasi Perusahaan Modern: Dilema Penyimpanan Data
Ste Nadin 14 Mei 2026