리소스
모든 CISO가 오늘 당장 추적해야 할 LLM 속성
작성자: Sarang Warudkar - 선임 기술 PMM(CASB & AI)
2026년 2월 18일 5 분 읽기

인공지능 도구는 이제 글쓰기, 분석, 회의 자동화, 소프트웨어 개발 등 일상 업무 전반에 영향을 미칩니다. 이러한 급속한 도입은 생산성 향상을 가져오지만, 대규모 언어 모델(LLM)의 동작으로 인해 새로운 보안 취약점을 발생시킵니다. 기존의 SaaS 점검만으로는 더 이상 충분하지 않습니다. 최고정보보안책임자(CISO)들은 이제 애플리케이션과 그 기반이 되는 모델을 동등한 주의로 평가합니다.
이 블로그는 기업 리스크를 형성하는 LLM 속성과 보안 리더들이 이를 통제하기 위해 활용할 수 있는 실질적인 단계를 설명합니다.
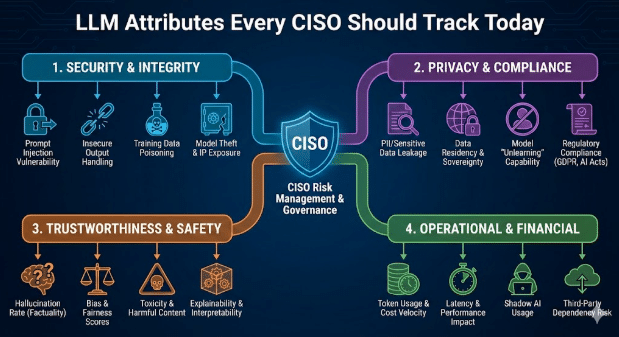
LLM 속성이 중요한 이유
대부분의 AI SaaS 제품은 타사 대규모 언어 모델(LLM)을 내장합니다. 이는 이중 의존성을 초래합니다. 앱이 모든 보안 검사를 통과하더라도, 그 밑에 있는 모델은 여전히 데이터를 노출하거나 안전하지 않은 코드를 생성하거나 민감한 워크플로를 유출할 수 있습니다. LLM 계층에 대한 명확한 가시성은 이러한 격차를 해소하고 AI 거버넌스를 현대적 위협에 부합하도록 합니다.
1. 애플리케이션 수준 AI 위험: 기초
모델을 검토하기 전에, AI SaaS 애플리케이션이 기업에서 기대하는 핵심 요구사항을 충족하는지 확인하십시오.
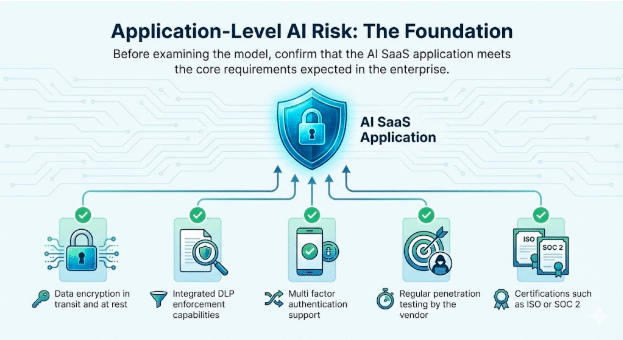
검증할 기준 속성
- 전송 중 및 저장 시 데이터 암호화
- 통합 DLP 시행 기능
- 다중 요소 인증 지원
- 공급업체의 정기적인 침투 테스트
- ISO 또는 SOC 2와 같은 인증
이러한 검증은 여전히 필수적입니다. 이는 서비스 자체에 대한 신뢰를 구축하고 안전한 AI 도입의 기반을 마련합니다.
2. LLM 행동: 새로운 위험 표면의 근원
LLM 속성은 실제 사용자와 적대적 프롬프트에 대한 애플리케이션의 반응 방식에 직접적인 영향을 미칩니다. CISO는 이제 모든 내장 모델에서 다음과 같은 행동을 추적합니다.
GenAI 및 LLM 통합
정확한 모델, 호스팅 지역, 업데이트 패턴을 확인하고 공급업체가 고객 데이터를 활용하여 모델을 미세 조정하는지 여부를 파악하십시오.
탈옥 노출
탈옥(Jailbreak)은 사용자가 LLM 안전 제어 기능을 우회하기 위해 프롬프트를 조작할 때 발생합니다. 흔히 사용되는 기법으로는 역할극, 계층적 지시문, 허구적 프레임 설정, 간접적 또는 암호화된 언어 사용 등이 있습니다. 이러한 상호작용은 정상적인 사용과 유사하기 때문에 기본적인 제어 기능을 종종 회피합니다. 탈옥 시도를 추적하면 보안 팀이 오용을 조기에 탐지하고, 안전 장치를 강화하며, 감사 시 선제적 거버넌스를 입증하는 데 도움이 됩니다.
예시
- 공격자가 챗봇을 속여 고객 계정의 MFA(다단계 인증)를 비활성화하는 방법을 설명하도록 유도합니다. 이는 민감한 데이터에 대한 직접적인 접근 경로를 열어주며, 합법적으로 보이는 워크플로우 내에서 신원 거버넌스를 무력화시킵니다.
악성코드 및 유해 코드 생성
LLM은 때때로 숨겨진 실행 경로나 정보 유출 루틴을 포함하는 코드를 생성합니다.
예시
- 엔지니어가 내부 서비스에 AI가 제안한 코드를 붙여넣습니다. 해당 코드에는 은밀한 데이터 유출이 포함되어 있습니다. 이로 인해 논리가 유효해 보이기 때문에 탐지되지 않은 침해 사고가 발생합니다.
독성, 편향 및 CBRN 배출 위험
모델은 민감하거나 적대적인 프롬프트를 제공받을 경우 안전하지 않은 텍스트를 생성할 수 있습니다. 안전, 규정 준수 또는 물리적 위험이 고려 대상인 사업부에서 이러한 행동을 추적하십시오.
예시
- 독성: 내부 지원 챗봇이 적대적인 프롬프트를 입력받은 후 에스컬레이션된 고객 불만 사항에 대해 모욕적이거나 위협적인 언어로 응답하여, 대화 기록이 저장되거나 공유될 경우 인사 및 브랜드 리스크를 초래합니다.
- 편향: 채용 팀이 대규모 언어 모델(LLM)을 활용해 지원자를 순위 매기는데, 해당 모델이 성별이나 카스트 지표가 포함된 프로필을 지속적으로 하향 조정하여 조직을 차별 및 감사 결과에 노출시킵니다.
- CBRN 산출물 위험: 연구개발 사용자가 화학 공정 개선에 대해 대규모 언어 모델(LLM)에 질의하면, 모델이 단계별 지침을 반환하는데 이는 제한된 화학 합성과 부합하여 규제 및 물리적 안전 노출을 초래합니다.
NIST 및 OWASP LLM 지침과의 정렬
NIST는 생성형 AI 프로파일을 발표했으며, 이는 책임 있는 AI 위험 관리의 기준이 되기 위해 빠르게 자리 잡고 있습니다. 보안 및 규정 준수 팀은 이제 모든 대규모 언어 모델 기반 애플리케이션이 이러한 기대 사항에 명확히 부합할 것을 요구하고 있습니다.
기업들은 직접적인 질문을 던지고 있다
- 인공지능의 사용 방식과 그 결과에 대해 누가 책임을 지는가
- 어떤 LLM 사용 사례가 명시적으로 허용되거나 금지되는가
- 훈련 및 미세 조정 데이터가 투명하게 공개되는지 여부
- 즉각적인 주입, 환각, 무단 데이터 접근과 같은 위험이 어떻게 처리되는지
이러한 질문에 명확한 답변이 없을 경우 감사 위험이 급격히 증가합니다. 의료 및 금융 서비스와 같은 규제 산업에서는 NIST 지침과의 불일치가 데이터 유출, 규제 벌금, 감사 실패 가능성을 높입니다.
동시에, OWASP LLM 애플리케이션 상위 10대 취약점은 기존 애플리케이션 보안 문제를 넘어서는 새로운 유형의 취약점을 기록하고 있습니다. 여기에는 프롬프트 주입, 안전하지 않은 출력 처리, 훈련 데이터 중독, 안전하지 않은 통합 등이 포함됩니다.
실제 사건들은 이미 이러한 위험을 반영하고 있습니다. 한 사례에서 SaaS 애플리케이션은 사용자가 AI 처리를 위해 문서를 업로드할 수 있도록 허용했습니다. 공격자가 파일 내에 숨겨진 명령어를 삽입하자 모델이 이를 실행했고, 결과적으로 기업의 민감한 데이터가 노출되었습니다. 이러한 시나리오들은 실제 운영 환경에서 발생하고 있으며, 이를 적극적으로 추적하고 완화하지 않는 조직은 중대한 보안 위험에 직면하게 됩니다.
예시
- 출력 검증이 없는 모델은 프롬프트 주입 시도에 노출된 관리자 키를 유출합니다. 이는 강력한 애플리케이션 수준 제어에도 불구하고 시스템 전체가 침해되는 결과를 초래합니다.
CISO들이 이러한 특성을 어떻게 실행으로 전환하는가
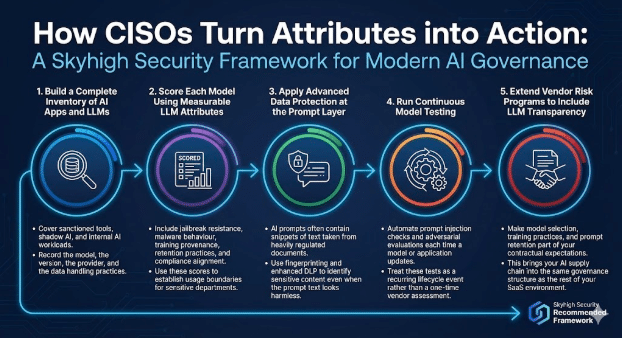
현대적인 AI 거버넌스 프로그램은 애플리케이션 검사와 모델 인식 제어 기능을 결합합니다.
Skyhigh Security 다음과 같은 프레임워크를Skyhigh Security .
1. AI 애플리케이션 및 대규모 언어 모델(LLM)의 완전한 목록 구축
승인된 도구, 섀도 AI 및 내부 AI 워크로드를 포함합니다.
모델, 버전, 공급자 및 데이터 처리 관행을 기록하십시오.
2. 측정 가능한 LLM 속성을 사용하여 각 모델을 평가합니다.
탈옥 방지, 악성코드 행동, 교육 출처, 보존 관행 및 규정 준수 정렬을 포함합니다. 이러한 점수를 활용하여 민감한 부서의 사용 범위를 설정하십시오.
3. 프롬프트 계층에서 고급 데이터 보호 적용
AI 프롬프트에는 종종 엄격히 규제되는 문서에서 발췌한 텍스트 조각이 포함됩니다. 프린트핑거링 및 강화된 DLP를 활용하여 프롬프트 텍스트가 무해해 보일 때에도 민감한 콘텐츠를 식별하십시오.
4. 지속적 모델 테스트 실행
모델 또는 애플리케이션이 업데이트될 때마다 프롬프트 주입 검사 및 적대적 평가를 자동화하십시오. 이러한 테스트를 일회성 공급업체 평가가 아닌 반복적인 라이프사이클 이벤트로 취급하십시오.
5. 공급업체 위험 관리 프로그램 확대: 대규모 언어 모델(LLM) 투명성 포함
모델 선택, 훈련 관행 및 프롬프트 보존을 계약상 기대 사항에 포함시키십시오. 이를 통해 AI 공급망이 SaaS 환경의 나머지 부분과 동일한 거버넌스 구조로 통합됩니다.
앞으로 나아갈 길
LLM은 기업이 AI를 활용하는 방식을 재편하며, CISO가 위험을 평가하는 방식도 재편합니다.
전통적인 애플리케이션 거버넌스에서 보안 팀은 두 가지 관심사를 분리합니다. 애플리케이션은 접근 제어, 데이터 보호, 로깅 및 규정 준수에 대한 기업 표준을 충족해야 합니다. 별도로, 기반 플랫폼은 신뢰성, 보안 및 운영 기대치를 충족해야 합니다.
LLM은 동일한 두 계층의 책임을 도입하지만, 더 높은 위험을 수반한다.
- 애플리케이션 계층에서 조직은 AI 기능이 사용자에게 노출되는 방식을 통제해야 합니다. 여기에는 기능 접근 권한 부여 대상, 제출 가능한 데이터 유형, 출력 공유 방식, 감사 및 조사를 위한 활동 기록 방식 등이 포함됩니다. 이러한 통제 수단은 익숙한 애플리케이션 보안 관행을 AI 기반 워크플로로 확장한 것입니다.
- 모델 계층에서 CISO는 LLM이 실제 환경에서 어떻게 동작하는지 평가해야 합니다. 여기에는 모델이 민감한 프롬프트를 처리하는 방식, 안전하지 않거나 편향된 출력을 생성하는지 여부, 데이터를 유지하거나 재사용하는 방법, 프롬프트 주입이나 데이터 오염과 같은 악용에 대한 복원력이 포함됩니다. 이러한 행동들은 기존 애플리케이션 테스트 범위를 벗어나며 명시적인 거버넌스가 필요합니다.
데이터 사용량, 안전성 행동, 가드레일 적용 범위, 실패 패턴과 같은 대규모 언어 모델(LLM) 속성을 추적함으로써 보안 책임자들은 성숙한 애플리케이션 프로그램에서 기대하는 것과 동일한 신뢰도를 확보할 수 있습니다. 이러한 가시성을 바탕으로 최고정보보안책임자(CISO)는 기업 전반에 걸쳐 보안, 개인정보 보호 및 규제 준수 약속을 유지하면서 더 광범위한 AI 도입을 지원할 수 있습니다.
저자 소개

사랑 와루드카르
수석 기술 제품 마케팅 매니저
Sarang Warudkar는 사이버 보안 분야에서 10년 이상 경력을 쌓은 노련한 제품 마케팅 관리자로, 기술 혁신을 시장의 요구사항에 맞추는 데 능숙합니다. 그는 CASB, DLP, AI 기반 위협 탐지와 같은 솔루션에 대한 깊은 전문 지식을 바탕으로 영향력 있는 시장 진출 전략과 고객 참여를 주도합니다. Sarang은 IIM 방갈로르에서 MBA를, 푸네 대학교에서 공학 학위를 취득하여 기술 및 전략적 통찰력을 겸비하고 있습니다.



인기 블로그
A Different Approach: Why the Answer to Browser Security Is Not a New Browser
Sarang Warudkar June 17, 2026
Skyhigh Security , 2026년 IRAP 평가에서 ‘PROTECTED’ 등급 Skyhigh Security
사랑 와루드카르와 스튜어트 베일리스 2026년 5월 21일
Skyhigh Security , SSE 클라우드 플랫폼 전체에 대한 SOC 2 Type II 인증 Skyhigh Security
사랑 와루드카르와 스튜어트 베일리스 2026년 4월 30일