ทรัพยากร
AI พื้นฐาน: ชั้นสำคัญที่มีความท้าทายด้านความปลอดภัย
โดย Sekhar Sarukkai - Cybersecurity@UC Berkeley
10 ตุลาคม 2567 5 อ่านนาที

ในบล็อกแรกในซีรีส์ของเราที่มีชื่อว่า “ AI Security: Customer Needs And Opportunities ” เราจะนำเสนอภาพรวมของเทคโนโลยี AI ทั้งสามระดับและกรณีการใช้งาน รวมถึงสรุปความท้าทายและโซลูชันด้านความปลอดภัยของ AI ในบล็อกที่สองนี้ เราจะพูดถึงความเสี่ยงเฉพาะที่เกี่ยวข้องกับ Layer 1: Foundational AI และการบรรเทาผลกระทบที่สามารถช่วยให้องค์กรใช้ประโยชน์จาก AI ให้เกิดประโยชน์ทางธุรกิจได้
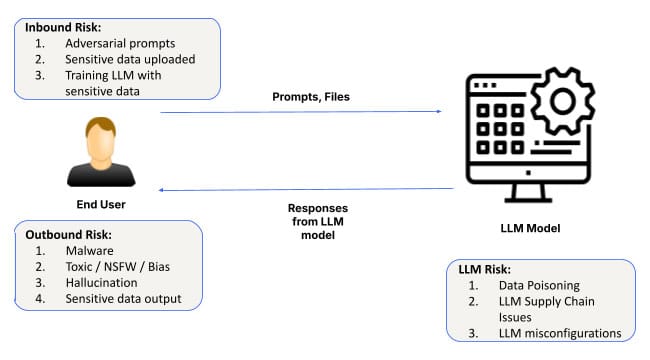
เนื่องจากปัญญาประดิษฐ์ (AI) ยังคงพัฒนาและเป็นที่ยอมรับ การประยุกต์ใช้จึงครอบคลุมอุตสาหกรรมต่างๆ ตั้งแต่การดูแลสุขภาพไปจนถึงการเงิน หัวใจสำคัญของระบบ AI ทุกระบบคือโมเดลพื้นฐานและโครงสร้างพื้นฐานซอฟต์แวร์เพื่อปรับแต่งโมเดลเหล่านั้น เลเยอร์นี้จัดเตรียมพื้นฐานสำหรับแอปพลิเคชัน AI ทั้งหมด ช่วยให้ระบบสามารถเรียนรู้จากข้อมูล ตรวจจับรูปแบบ และทำนาย อย่างไรก็ตาม แม้จะมีความสำคัญ แต่เลเยอร์ AI พื้นฐานก็มีความเสี่ยงเช่นกัน ตั้งแต่การโจมตีทางวิศวกรรมอย่างรวดเร็ว การกำหนดค่าผิดพลาด ไปจนถึงการรั่วไหลของข้อมูล ความท้าทายด้านความปลอดภัยในเลเยอร์นี้สามารถส่งผลกระทบในวงกว้างได้
มาเจาะลึกเรื่องความเสี่ยงด้านความปลอดภัยที่เกี่ยวข้องกับ AI พื้นฐานและสิ่งที่ธุรกิจต่างๆ จำเป็นต้องระวังเมื่อนำโซลูชันที่ขับเคลื่อนด้วย AI มาใช้
ความเสี่ยงด้านความปลอดภัยในระดับพื้นฐานของ AI
1. การโจมตีทางวิศวกรรมที่รวดเร็ว
ความเสี่ยงที่เกิดขึ้นบ่อยที่สุดอย่างหนึ่งในระดับ Foundational AI คือวิศวกรรมที่รวดเร็ว ซึ่งผู้โจมตีจะบิดเบือนข้อมูลอินพุตของ AI เพื่อสร้างผลลัพธ์ที่ไม่ได้ตั้งใจหรือเป็นอันตราย การโจมตีเหล่านี้ใช้ประโยชน์จากช่องโหว่ในการตีความและตอบสนองต่อคำเตือนของโมเดล AI ทำให้ผู้ไม่หวังดีสามารถหลีกเลี่ยงโปรโตคอลความปลอดภัยได้
เทคนิคใหม่ๆ เช่น SkeletonKey และ CrescendoMation ทำให้การออกแบบอย่างรวดเร็วกลายเป็นภัยคุกคามที่เพิ่มมากขึ้น โดยระบบ AI แบบ “เจลเบรก” ในรูปแบบต่างๆ กลายเป็นเรื่องธรรมดา การโจมตีเหล่านี้สามารถพบได้บนเว็บมืด โดยมีเครื่องมืออย่าง WormGPT , FraudGPT และ EscapeGPT ที่ขายให้กับแฮกเกอร์อย่างเปิดเผย เมื่อโมเดล AI ถูกบุกรุก ก็สามารถสร้างการตอบสนองที่ทำให้เข้าใจผิดหรือเป็นอันตรายได้ ส่งผลให้เกิดการละเมิดข้อมูลหรือระบบล้มเหลว
ตัวอย่างเช่น ผู้โจมตีสามารถแทรกคำเตือนลงในระบบ AI บริการลูกค้า โดยหลีกเลี่ยงข้อจำกัดของโมเดลในการเข้าถึงข้อมูลที่ละเอียดอ่อนของลูกค้าหรือจัดการเอาท์พุตเพื่อทำให้การทำงานหยุดชะงัก
เพื่อบรรเทาความเสี่ยงนี้ องค์กรต่างๆ จะต้องใช้กลไกการตรวจสอบข้อมูลอินพุตที่แข็งแกร่ง และตรวจสอบระบบ AI เพื่อค้นหาช่องโหว่ที่อาจเกิดขึ้นเป็นประจำ โดยเฉพาะอย่างยิ่งเมื่อมีการใช้คำเตือนเพื่อควบคุมกระบวนการทางธุรกิจที่สำคัญ
2. การรั่วไหลของข้อมูล
การรั่วไหลของข้อมูลเป็นอีกประเด็นสำคัญในชั้น Foundational AI เมื่อองค์กรต่างๆ ใช้โมเดล AI สำหรับงานต่างๆ เช่น การสร้างข้อมูลเชิงลึกจากข้อมูลที่ละเอียดอ่อน ก็มีความเสี่ยงที่ข้อมูลบางส่วนอาจเปิดเผยโดยไม่ได้ตั้งใจระหว่างการโต้ตอบกับ AI โดยเฉพาะอย่างยิ่งในการปรับแต่งโมเดลหรือระหว่างการสนทนาที่ยาวนานกับ LLM (Large Language Models)
ตัวอย่างที่น่าสังเกตเกิดขึ้นเมื่อ วิศวกรของ Samsung รั่วไหลข้อมูลสำคัญขององค์กรโดยไม่ได้ตั้งใจผ่านการโต้ตอบกับ ChatGPT เหตุการณ์ดังกล่าวเน้นย้ำถึงความสำคัญของการจัดการข้อมูลด่วนเป็นแบบไม่ส่วนตัวตามค่าเริ่มต้น เนื่องจากข้อมูลดังกล่าวสามารถรวมเข้ากับข้อมูลฝึกอบรมของ AI ได้อย่างง่ายดาย แม้ว่าเราจะเห็นความก้าวหน้าอย่างต่อเนื่องในการปกป้องความเป็นส่วนตัวในเลเยอร์โมเดลพื้นฐาน แต่คุณยังคงต้อง เลือกไม่เข้าร่วม เพื่อให้แน่ใจว่าไม่มีข้อมูลด่วนใด ๆ ที่จะเข้าสู่โมเดล
นอกจากนี้ วิธีการขโมยข้อมูลที่เคยถูกใช้ประโยชน์ในอดีตสามารถนำไปใช้ได้ง่ายขึ้นในบริบทของการสนทนาระยะยาวกับ LLM การรับรู้ถึงปัญหาต่างๆ เช่น ช่องโหว่ ของรูปภาพ ในแชทบ็อต Bing และ ChatGPT จะต้องได้รับการแก้ไข โดยเฉพาะอย่างยิ่งกับการใช้งาน LLM แบบส่วนตัว
เทคนิคการขโมยข้อมูลที่เคยกำหนดเป้าหมายไปที่ระบบดั้งเดิมมาโดยตลอดนั้นยังได้รับการปรับให้เหมาะกับสภาพแวดล้อม AI อีกด้วย ตัวอย่างเช่น การโต้ตอบกับแชทบ็อตที่ดำเนินมายาวนานอาจถูกผู้โจมตีใช้ประโยชน์โดยใช้กลวิธีต่างๆ เช่น การโจมตี ด้วยมาร์กดาวน์รูปภาพ (ตามที่เห็นใน ChatGPT ) เพื่อขโมยข้อมูลที่ละเอียดอ่อนอย่างลับๆ เมื่อเวลาผ่านไป
องค์กรต่างๆ สามารถจัดการความเสี่ยงนี้ได้โดยใช้หลักการจัดการข้อมูลที่เข้มงวดและใช้การควบคุมเพื่อให้แน่ใจว่าข้อมูลที่ละเอียดอ่อนจะไม่ถูกเปิดเผยโดยไม่ได้ตั้งใจผ่านโมเดล AI
3. อินสแตนซ์ที่กำหนดค่าไม่ถูกต้อง
การกำหนดค่าที่ไม่ถูกต้องเป็นแหล่งที่มาของช่องโหว่ด้านความปลอดภัยโดยทั่วไป และสิ่งนี้เป็นจริงโดยเฉพาะในระดับ AI พื้นฐาน เมื่อพิจารณาจากการใช้งานระบบ AI อย่างรวดเร็ว องค์กรต่างๆ จำนวนมากประสบปัญหาในการกำหนดค่าสภาพแวดล้อม AI ของตนให้เหมาะสม ทำให้โมเดลต่างๆ เสี่ยงต่อภัยคุกคามที่อาจเกิดขึ้น
การกำหนดค่าอินสแตนซ์ AI ไม่ถูกต้อง เช่น การอนุญาตให้ใช้ปลั๊กอินของบุคคลที่สามที่ไม่น่าเชื่อถือ การเปิดใช้งานการรวมข้อมูลภายนอกโดยไม่มีการควบคุมที่เหมาะสม หรือการมอบสิทธิ์ที่มากเกินไปให้กับโมเดล AI อาจส่งผลให้เกิดการละเมิดข้อมูลจำนวนมาก ในโมเดลความรับผิดชอบร่วมกัน องค์กรอาจล้มเหลวในการนำข้อจำกัดที่จำเป็นมาใช้ ซึ่งเพิ่มความเสี่ยงของการเข้าถึงโดยไม่ได้รับอนุญาตหรือการขโมยข้อมูล
ตัวอย่างเช่น ChatGPT อนุญาตให้ปลั๊กอินรวมเข้ากับบริการของบุคคลที่สาม ซึ่งอาจเป็น แหล่งสำคัญของการรั่วไหลของข้อมูล หากปลั๊กอินที่ไม่น่าเชื่อถือเชื่อมต่อกับอินสแตนซ์ขององค์กรโดยไม่ได้ตั้งใจ ในทำนองเดียวกัน การกำหนดค่าการควบคุมการเข้าถึงที่ไม่เหมาะสมอาจทำให้ผู้ใช้ที่ไม่ได้รับอนุญาตเข้าถึงข้อมูลที่ละเอียดอ่อนผ่านระบบ AI ได้
แม้ว่าการทำงานเป็นทีมสีแดงจะไม่ใช่แนวคิดใหม่ แต่ก็มีความสำคัญอย่างยิ่งในทุกชั้นของ AI เนื่องจาก LLM ทำหน้าที่เป็นกล่องดำและผลลัพธ์ของ LLM นั้นไม่สามารถคาดเดาได้ ตัวอย่างเช่น การวิจัยจาก Anthropic แสดงให้เห็นว่า LLM อาจกลายเป็น ตัวแทนที่หลับใหล โดยมีการโจมตีที่ซ่อนอยู่ในน้ำหนักของโมเดลซึ่งอาจปรากฏขึ้นโดยไม่คาดคิด
เพื่อลดความเสี่ยงนี้ องค์กรต่างๆ ควรปฏิบัติตามแนวทางปฏิบัติที่ดีที่สุดในการกำหนดค่า AI โดยจำกัดการรวมบริการของบุคคลที่สาม จำกัดการอนุญาต และตรวจสอบการกำหนดค่าสภาพแวดล้อม AI เป็นประจำ Skyhigh Security การใช้งานโซลูชันแอปพลิเคชัน AI อย่างปลอดภัย นั้นมอบเครื่องมือและแนวทางปฏิบัติที่ดีที่สุดเพื่อให้แน่ใจว่าระบบ AI ได้รับการกำหนดค่าและปกป้องอย่างถูกต้อง
การเสริมสร้างความปลอดภัย AI ในเลเยอร์ 1
ความเสี่ยงด้านความปลอดภัยดังกล่าวข้างต้นจำเป็นต้องได้รับการจัดการตามกรณีการใช้งานที่แตกต่างกัน สำหรับการใช้งาน LLM แบบสาธารณะภายในองค์กร Secure Service Edge (พร็อกซี SSE ล่วงหน้า) เป็นแพลตฟอร์มตรรกะที่ใช้ขยายการควบคุมไปยังแอปพลิเคชัน SaaS AI เนื่องจากองค์กรต่างๆ ใช้แพลตฟอร์มนี้เพื่อค้นหา ควบคุมการเข้าถึง และปกป้องข้อมูลไปยังแอปพลิเคชันและบริการ SaaS ทั้งหมดอยู่แล้ว ในทางกลับกัน สำหรับการใช้งานบนโครงสร้างพื้นฐานส่วนตัว ไฟร์วอลล์ LLM ที่เป็นการผสมผสานระหว่างพร็อกซี SSE ย้อนกลับ (หรือผ่าน API ของ LLM) และการ์ดเรล AI จะเป็นรูปแบบที่เหมาะสมในการบรรลุความปลอดภัยแบบ Zero Trust การค้นพบอย่างต่อเนื่อง การทำงานเป็นทีม และการตรวจสอบการกำหนดค่าจะมีความสำคัญเช่นกัน ไม่ว่าจะใช้รูปแบบการใช้งานแบบใด

รูปภาพด้านบนแสดงสถาปัตยกรรมที่ครอบคลุมสำหรับการรักษาความปลอดภัยการใช้งาน LLM จากภายในองค์กรหรือผู้ใช้และอุปกรณ์ที่เชื่อถือได้ แนวทางที่คล้ายกันสำหรับลูกค้าและอุปกรณ์ที่ไม่ได้รับการจัดการจะเน้นที่โฟลว์ด้านล่างเป็นหลัก ซึ่งรวมถึงพร็อกซีแบบย้อนกลับเท่านั้น
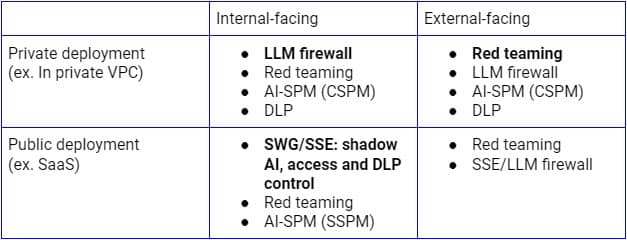
การจัดการความเสี่ยงด้านความปลอดภัยเหล่านี้ในช่วงเริ่มต้นการใช้งาน AI พื้นฐานถือเป็นสิ่งสำคัญในการประกันความสำเร็จและความปลอดภัยของระบบ AI เพื่อเสริมสร้างความปลอดภัยของ AI ในชั้นพื้นฐานนี้ องค์กรต่างๆ ควรดำเนินการดังต่อไปนี้:
- ดำเนินการตรวจสอบตามปกติ : ให้แน่ใจว่าระบบ AI ได้รับการตรวจสอบเป็นประจำเพื่อตรวจสอบช่องโหว่การแทรกอย่างรวดเร็ว การกำหนดค่าผิดพลาด และปัญหาการจัดการข้อมูล
- ใช้การตรวจสอบข้อมูลอินพุต : ใช้กลไกที่แข็งแกร่งเพื่อตรวจสอบคำเตือนและอินพุต ช่วยลดความเสี่ยงจากการโจมตีทางวิศวกรรมคำเตือน
- ใช้มาตรการปกป้องข้อมูล : สร้างกรอบการกำกับดูแลข้อมูลที่แข็งแกร่งเพื่อลดความเสี่ยงของการรั่วไหลของข้อมูลระหว่างการโต้ตอบ AI
- สภาพแวดล้อม AI ที่ปลอดภัย : ปฏิบัติตามแนวทางปฏิบัติที่ดีที่สุดในการกำหนดค่าระบบ AI โดยเฉพาะอย่างยิ่งเมื่อรวมปลั๊กอินหรือบริการของบุคคลที่สาม
เส้นทางข้างหน้า: การรักษาความปลอดภัย AI ตั้งแต่พื้นฐาน
AI พื้นฐานเป็นกระดูกสันหลังสำหรับแอปพลิเคชัน AI ขั้นสูงมากมาย แต่ยังก่อให้เกิดความเสี่ยงด้านความปลอดภัยที่สำคัญ เช่น การโจมตีทางวิศวกรรมที่รวดเร็ว การรั่วไหลของข้อมูล และการกำหนดค่าผิดพลาด เนื่องจาก AI ยังคงมีบทบาทสำคัญในการขับเคลื่อนการสร้างสรรค์นวัตกรรมในอุตสาหกรรมต่างๆ ธุรกิจต่างๆ จึงต้องให้ความสำคัญกับความปลอดภัยตั้งแต่เริ่มต้น โดยเริ่มจากชั้นพื้นฐานนี้
บล็อกถัดไปในซีรีส์ของเราจะสำรวจความต้องการและโอกาสด้านความปลอดภัยที่เกี่ยวข้องกับ Layer 2: AI Copilots ผู้ช่วยเสมือน และเครื่องมือเพิ่มประสิทธิภาพการทำงานที่สามารถช่วยแนะนำการตัดสินใจและทำให้การทำงานที่หลากหลายเป็นระบบอัตโนมัติ หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับการรักษาความปลอดภัยแอปพลิเคชัน AI ของคุณและการลดความเสี่ยง โปรดดูโซลูชัน AI ของ Skyhigh
บล็อกอื่นๆ ในซีรี่ส์นี้:
- ส่วนที่ 1 – ความปลอดภัยของ AI: ความต้องการและโอกาสของลูกค้า
- ส่วนที่ 2 – AI พื้นฐาน: ชั้นสำคัญที่มีความท้าทายด้านความปลอดภัย
- ส่วนที่ 3 – ความเสี่ยงด้านความปลอดภัยและความท้าทายกับ AI Copilots
เนื้อหาที่เกี่ยวข้อง



บล็อกที่กำลังได้รับความนิยม
Skyhigh Security Achieves CSA STAR Level 2 Certification, Raising the Bar for Independent Cloud Security Assurance
Stuart Bayliss and Sarang Warudkar June 25, 2026
A Different Approach: Why the Answer to Browser Security Is Not a New Browser
Sarang Warudkar June 17, 2026
Skyhigh Security การประเมิน IRAP ที่ระดับ PROTECTED สำหรับปี 2026
สารัง วรุธกฤา และ สจวร์ต เบลลิส 21 พฤษภาคม 2026
AI Tools Created a Security Gap Your Network Cannot See. Browser Controls Close it.
สารัง วรุธกฤා 19 พฤษภาคม 2026
การรักษาความปลอดภัยของการกระจายตัวขององค์กรสมัยใหม่: ปัญหาการโฮสต์ข้อมูล
สเต นาดิน 14 พฤษภาคม 2026