Ressourcen
Grundlegende KI: Eine kritische Schicht mit Sicherheitsherausforderungen
Von Sekhar Sarukkai - Cybersecurity@UC Berkeley
Oktober 10, 2024 5 Minute gelesen

Im ersten Blog unserer Serie, "KI-Sicherheit: Kundenbedürfnisse und Chancen" haben wir einen Überblick über die drei Schichten des KI-Technologiestapels und ihre Anwendungsfälle sowie eine Zusammenfassung der KI-Sicherheitsherausforderungen und -lösungen gegeben. In diesem zweiten Blog befassen wir uns mit den spezifischen Risiken, die mit Schicht 1 verbunden sind: Grundlegende KI und Abhilfemaßnahmen, die Unternehmen helfen können, die vielen Vorteile von KI zu ihrem geschäftlichen Vorteil zu nutzen.
Künstliche Intelligenz (KI) entwickelt sich weiter und fasst immer mehr Fuß. Ihre Anwendungen erstrecken sich über Branchen vom Gesundheitswesen bis zum Finanzwesen. Das Herzstück eines jeden KI-Systems sind die grundlegenden Modelle und die Software-Infrastruktur zur Anpassung dieser Modelle. Diese Schicht bildet die Grundlage für alle KI-Anwendungen und ermöglicht es den Systemen, aus Daten zu lernen, Muster zu erkennen und Vorhersagen zu treffen. Trotz ihrer Bedeutung ist die KI-Basisschicht jedoch nicht ohne Risiken. Von Prompt-Engineering-Angriffen über Fehlkonfigurationen bis hin zu Datenlecks - Sicherheitsprobleme auf dieser Ebene können weitreichende Folgen haben.
Lassen Sie uns tief in die Sicherheitsrisiken eintauchen, die mit Foundational AI verbunden sind und worauf Unternehmen achten müssen, wenn sie KI-gesteuerte Lösungen einführen.
Sicherheitsrisiken auf der grundlegenden KI-Ebene
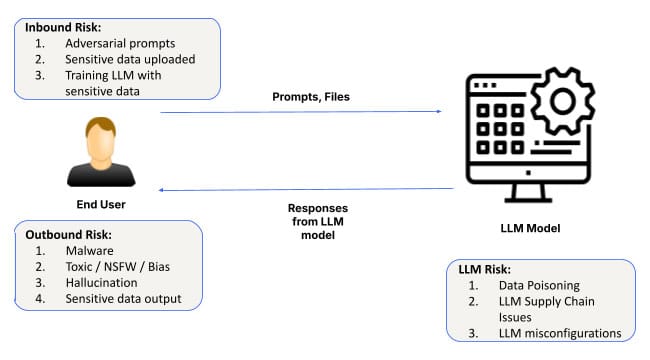
1. Prompte technische Angriffe
Eines der häufigsten Risiken auf der Ebene der grundlegenden KI ist das Prompt-Engineering, bei dem Angreifer KI-Eingaben manipulieren, um unbeabsichtigte oder schädliche Ausgaben zu erzeugen. Diese Angriffe nutzen Schwachstellen in der Art und Weise aus, wie KI-Modelle Eingabeaufforderungen interpretieren und darauf reagieren, und ermöglichen es böswilligen Akteuren, Sicherheitsprotokolle zu umgehen.
Neue Techniken wie SkeletonKey und CrescendoMation haben Prompt-Engineering zu einer wachsenden Bedrohung gemacht, wobei verschiedene Formen des "Gefängnisausbruchs" von KI-Systemen alltäglich geworden sind. Diese Angriffe sind im Dark Web zu finden, wo Tools wie WormGPT, FraudGPT und EscapeGPT offen an Hacker verkauft werden. Sobald ein KI-Modell kompromittiert ist, kann es irreführende oder gefährliche Antworten geben, die zu Datenverletzungen oder Systemausfällen führen.
Ein Angreifer könnte beispielsweise Eingabeaufforderungen in ein KI-System für den Kundendienst einschleusen und so die Einschränkungen des Modells umgehen, um auf sensible Kundendaten zuzugreifen oder die Ausgaben zu manipulieren, um den Betrieb zu stören.
Um dieses Risiko zu minimieren, müssen Unternehmen robuste Mechanismen zur Eingabevalidierung implementieren und KI-Systeme regelmäßig auf potenzielle Schwachstellen überprüfen, insbesondere wenn Eingabeaufforderungen zur Steuerung wichtiger Geschäftsprozesse verwendet werden.
2. Datenleck
Datenlecks sind ein weiteres großes Problem auf der Ebene der grundlegenden KI. Wenn Unternehmen KI-Modelle für Aufgaben wie die Gewinnung von Erkenntnissen aus sensiblen Daten verwenden, besteht das Risiko, dass einige dieser Informationen während der KI-Interaktionen versehentlich preisgegeben werden. Dies gilt insbesondere für die Feinabstimmung des Modells oder während längerer Unterhaltungen mit LLMs (Large Language Models).
Ein bemerkenswertes Beispiel war, als Samsung-Ingenieure durch Interaktionen mit ChatGPT versehentlich sensible Unternehmensdaten weitergaben. Solche Vorfälle unterstreichen, wie wichtig es ist, Prompt-Daten standardmäßig als nicht-privat zu behandeln, da sie leicht in die Trainingsdaten der KI aufgenommen werden könnten. Auch wenn wir weitere Fortschritte beim Schutz der Privatsphäre auf der Ebene des Basismodells sehen, müssen Sie sich immer noch abmelden, um sicherzustellen, dass keine Prompt-Daten in das Modell einfließen.
Darüber hinaus könnten historisch ausgenutzte Möglichkeiten der Datenexfiltration im Rahmen einer lang andauernden Konversation mit LLMs leichter eingesetzt werden. Auch Probleme wie die Ausnutzung von Image Markdown im Bing-Chatbot und ChatGPT müssen beachtet werden, insbesondere bei der privaten Nutzung von LLMs.
Techniken zur Datenexfiltration, die in der Vergangenheit auf traditionelle Systeme abzielten, werden auch für KI-Umgebungen angepasst. So könnten Angreifer beispielsweise lang andauernde Chatbot-Interaktionen mit Taktiken wie Image Markdown Exploits (wie in ChatGPT) ausnutzen, um im Laufe der Zeit heimlich sensible Daten zu extrahieren.
Unternehmen können diesem Risiko begegnen, indem sie strenge Richtlinien für den Umgang mit Daten einführen und Kontrollen implementieren, um sicherzustellen, dass sensible Informationen nicht versehentlich durch KI-Modelle offengelegt werden.
3. Fehlkonfigurierte Instanzen
Fehlkonfigurationen sind eine häufige Quelle für Sicherheitsschwachstellen, und dies gilt insbesondere für die KI-Grundlagenebene. Angesichts des schnellen Einsatzes von KI-Systemen fällt es vielen Unternehmen schwer, ihre KI-Umgebungen richtig zu konfigurieren, so dass die Modelle potenziellen Bedrohungen ausgesetzt sind.
Falsch konfigurierte KI-Instanzen - wie z.B. das Zulassen nicht vertrauenswürdiger Plugins von Drittanbietern, das Aktivieren externer Datenintegration ohne angemessene Kontrollen oder das Erteilen übermäßiger Berechtigungen für KI-Modelle - können zu erheblichen Datenverletzungen führen. In Modellen mit geteilter Verantwortung versäumen es Unternehmen möglicherweise auch, die notwendigen Beschränkungen zu implementieren, was das Risiko eines unbefugten Zugriffs oder einer Datenexfiltration erhöht.
ChatGPT ermöglicht beispielsweise die Integration von Plugins mit Diensten von Drittanbietern, was eine große Quelle für Datenlecks sein kann, wenn nicht vertrauenswürdige Plugins versehentlich mit Unternehmensinstanzen verbunden werden. Ebenso können unsachgemäße Konfigurationen der Zugriffskontrolle dazu führen, dass unbefugte Benutzer über KI-Systeme Zugriff auf sensible Daten erhalten.
Red Teaming ist zwar kein neues Konzept, aber es ist auf allen Ebenen des KI-Stacks besonders wichtig, da LLMs als Blackboxen fungieren und ihre Ergebnisse nicht vorhersehbar sind. So haben Forschungsarbeiten von Anthropic gezeigt, dass LLMs zu Schläferagenten werden können, deren Angriffe in den Modellgewichten versteckt sind und unerwartet auftauchen können.
Um dieses Risiko zu verringern, sollten Unternehmen Best Practices für die KI-Konfiguration befolgen, indem sie die Integration von Drittanbieterdiensten begrenzen, Berechtigungen einschränken und die Konfigurationen der KI-Umgebung regelmäßig überprüfen. Skyhigh SecurityDie Lösungen für die sichere Nutzung von KI-Anwendungen bieten die Tools und Best Practices, um sicherzustellen, dass KI-Systeme richtig konfiguriert und geschützt sind.
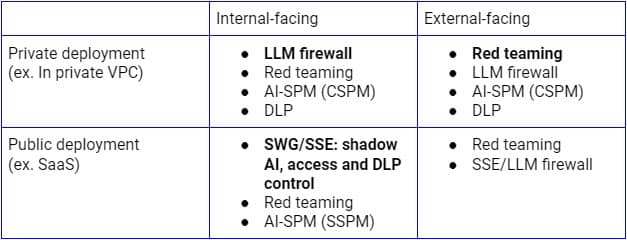
Verstärkung der KI-Sicherheit auf Ebene 1
Die oben genannten Sicherheitsrisiken müssen auf der Grundlage verschiedener Anwendungsfälle angegangen werden. Für interne öffentliche LLM-Implementierungen ist Secure Service Edge (SSE-Forward-Proxy) die logische Plattform, um die Kontrollen auf SaaS-KI-Anwendungen auszuweiten, da Unternehmen sie bereits für die Erkennung, die Zugriffskontrolle und den Schutz von Daten für alle SaaS-Anwendungen und -Dienste verwenden. Auf der anderen Seite ist eine LLM-Firewall, die eine Kombination aus SSE-Reverse-Proxy (oder über LLM-APIs) und KI-Leitplanken ist, für die Bereitstellung auf einer privaten Infrastruktur das richtige Paradigma, um Zero Trust-Sicherheit zu erreichen. Unabhängig vom Bereitstellungsmodell werden auch kontinuierliche Erkennung, Red Teaming und Konfigurationsprüfungen von entscheidender Bedeutung sein.

Die obige Abbildung veranschaulicht eine umfassende Architektur zur Sicherung der LLM-Nutzung innerhalb des Unternehmens oder von vertrauenswürdigen Benutzern und Geräten. Ein ähnlicher Ansatz für Kunden und nicht verwaltete Geräte konzentriert sich in erster Linie auf den unteren Fluss, der nur den Reverse-Proxy umfasst.
Die frühzeitige Behebung dieser Sicherheitsrisiken bei der Einführung von KI ist entscheidend für den Erfolg und die Sicherheit von KI-Systemen. Um die KI-Sicherheit auf dieser grundlegenden Ebene zu stärken, sollten Unternehmen:
- Führen Sie regelmäßige Audits durch: Stellen Sie sicher, dass KI-Systeme regelmäßig auf Schwachstellen, Fehlkonfigurationen und Probleme im Umgang mit Daten überprüft werden.
- Implementieren Sie eine Eingabeüberprüfung: Verwenden Sie robuste Mechanismen zur Validierung von Eingabeaufforderungen und Eingaben, um das Risiko von Prompt-Engineering-Angriffen zu verringern.
- Ergreifen Sie Maßnahmen zum Schutz von Daten: Führen Sie strenge Data-Governance-Rahmenwerke ein, um das Risiko von Datenverlusten bei KI-Interaktionen zu minimieren.
- Sichern Sie KI-Umgebungen: Befolgen Sie die besten Praktiken für die Konfiguration von KI-Systemen, insbesondere bei der Integration von Plugins oder Diensten von Drittanbietern.
Der Weg nach vorn: KI von Grund auf absichern
Grundlegende KI dient als Rückgrat für viele fortschrittliche KI-Anwendungen, birgt aber auch erhebliche Sicherheitsrisiken, darunter Soforteingriffe, Datenlecks und Fehlkonfigurationen. Da KI weiterhin eine zentrale Rolle bei der Förderung von Innovationen in allen Branchen spielt, müssen Unternehmen der Sicherheit von Anfang an Priorität einräumen - und zwar auf dieser grundlegenden Ebene.
Im nächsten Blog unserer Serie werden wir uns mit den Sicherheitsbedürfnissen und -möglichkeiten im Zusammenhang mit Layer 2 befassen: KI-Kopiloten, virtuelle Assistenten und Produktivitätswerkzeuge, die bei der Entscheidungsfindung helfen und eine Vielzahl von Aufgaben automatisieren können. Wenn Sie mehr über die Sicherung Ihrer KI-Anwendungen und die Minderung von Risiken erfahren möchten, informieren Sie sich über die KI-Lösungen von Skyhigh.
Andere Blogs in dieser Serie:
- Teil 1 - KI-Sicherheit: Kundenbedürfnisse und Chancen
- Teil 2 - Grundlegende KI: Eine kritische Schicht mit Sicherheitsherausforderungen
- Teil 3 - Sicherheitsrisiken und Herausforderungen mit KI-Kopiloten
Verwandter Inhalt

Skyhigh Security Achieves CSA STAR Level 2 Certification, Raising the Bar for Independent Cloud Security Assurance

A Different Approach: Why the Answer to Browser Security Is Not a New Browser

Skyhigh Security seine IRAP-Bewertung auf der Stufe „PROTECTED“ für das Jahr 2026
Laufende Blogs
Skyhigh Security Achieves CSA STAR Level 2 Certification, Raising the Bar for Independent Cloud Security Assurance
Stuart Bayliss and Sarang Warudkar June 25, 2026
A Different Approach: Why the Answer to Browser Security Is Not a New Browser
Sarang Warudkar June 17, 2026
Skyhigh Security seine IRAP-Bewertung auf der Stufe „PROTECTED“ für das Jahr 2026
Sarang Warudkar und Stuart Bayliss 21. Mai 2026
AI Tools Created a Security Gap Your Network Cannot See. Browser Controls Close it.
Sarang Warudkar 19. Mai 2026
Die Fragmentierung moderner Unternehmen bewältigen: Das Dilemma des Datenhostings
Ste Nadin 14. Mai 2026