リソース
基盤AI:セキュリティ課題を伴う重要なレイヤー
セカール・サルカイ - カリフォルニア大学バークレー校サイバーセキュリティ
2024年10月10日 5 分で読めます

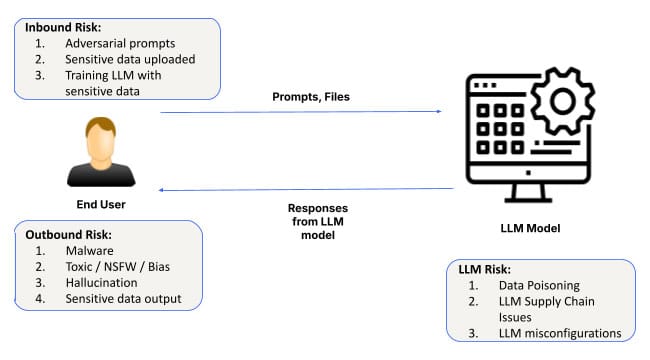
シリーズの最初のブログ「AIセキュリティ:顧客のニーズと機会」では、AIテクノロジースタックの3つのレイヤーとそのユースケース、およびAIセキュリティの課題とソリューションの概要を説明しました。この2番目のブログでは、レイヤー1である基盤AIに関連する特定のリスクと、組織がAIの多くの利点をビジネス上の優位性に活用するのに役立つ緩和策について取り上げます。
人工知能(AI)が進化を続け、その足場を固めるにつれて、その応用はヘルスケアから金融まで幅広い産業に及んでいます。あらゆるAIシステムの中核には、基盤モデルとそれらのモデルをカスタマイズするためのソフトウェアインフラストラクチャがあります。このレイヤーは、すべてのAIアプリケーションの基盤を提供し、システムがデータから学習し、パターンを検出し、予測を行うことを可能にします。しかし、その重要性にもかかわらず、基盤AIレイヤーにはリスクがないわけではありません。プロンプトエンジニアリング攻撃から、設定ミス、データ漏洩に至るまで、このレイヤーにおけるセキュリティ課題は広範囲にわたる影響を及ぼす可能性があります。
基盤AIに関連するセキュリティリスクと、企業がAI駆動型ソリューションを導入する際に注意すべき点について深く掘り下げてみましょう。
AI基盤レイヤーのセキュリティ・リスク
1. プロンプトエンジニアリング攻撃
基盤AIレイヤーにおける最も一般的なリスクの1つはプロンプトエンジニアリングであり、攻撃者はAI入力を操作して意図しない、または有害な出力を生成します。これらの攻撃は、AIモデルがプロンプトを解釈し応答する方法の脆弱性を悪用し、悪意のあるアクターがセキュリティプロトコルを回避することを可能にします。
SkeletonKeyやCrescendoMationなどの新しい技術により、プロンプトエンジニアリングは増大する脅威となり、AIシステムのさまざまな形式の「ジェイルブレイク」が一般的になっています。これらの攻撃はダークウェブで見られ、WormGPT、FraudGPT、EscapeGPTなどのツールがハッカーに公然と販売されています。AIモデルが侵害されると、誤解を招く、または危険な応答を生成し、データ漏洩やシステム障害につながる可能性があります。
例えば、攻撃者は顧客サービスAIシステムにプロンプトを注入し、モデルの制約を回避して機密性の高い顧客データにアクセスしたり、出力を操作して運用上の混乱を引き起こしたりする可能性があります。
このリスクを軽減するため、組織は堅牢な入力検証メカニズムを実装し、特にプロンプトが重要なビジネスプロセスを制御するために使用される場合、潜在的な脆弱性がないかAIシステムを定期的に監査する必要があります。
2. データ漏洩
データ漏洩は、基盤AIレイヤーにおけるもう1つの重要な懸念事項です。組織が機密データから洞察を生成するなどのタスクにAIモデルを使用する場合、AIとのやり取り中にこの情報の一部が意図せず公開されるリスクがあります。これは、モデルのファインチューニングやLLM(大規模言語モデル)との長時間の会話中に特に顕著です。
注目すべき例として、SamsungのエンジニアがChatGPTとのやり取りを通じて機密性の高い企業データを誤って漏洩させた事例があります。このような事例は、プロンプトデータがAIのトレーニングデータに容易に組み込まれる可能性があるため、デフォルトで非プライベートとして扱うことの重要性を強調しています。基盤モデルレイヤーにおけるプライバシー保護の継続的な進歩が見られる一方で、プロンプトデータがモデルに組み込まれないようにするためには、依然としてオプトアウトする必要があります。
さらに、LLMとの長時間の会話においては、過去に悪用されたデータ流出の手法がより容易に展開される可能性があります。Bingチャットボットにおける画像マークダウンの悪用やChatGPTのような問題も、特にLLMのプライベート展開においては対処する必要があります。
従来システムを標的としてきたデータ流出の手法は、AI環境向けにも応用されています。例えば、長時間のチャットボットとのやり取りは、攻撃者によって画像マークダウンの悪用(ChatGPTで見られるような)といった手口を使って悪用され、時間をかけて機密データを密かに抽出される可能性があります。
組織は、厳格なデータ処理ポリシーを採用し、AIモデルを通じて機密情報が意図せず公開されないようにするための制御を実装することで、このリスクに対処できます。
3. 設定ミスのあるインスタンス
設定ミスはセキュリティ脆弱性の一般的な原因であり、これはFoundational AI層において特に顕著です。AIシステムの急速な展開を考えると、多くの組織はAI環境を適切に設定するのに苦労しており、モデルが潜在的な脅威にさらされることになります。
信頼できないサードパーティ製プラグインの許可、適切な制御なしでの外部データ統合の有効化、AIモデルへの過剰な権限付与など、設定ミスのあるAIインスタンスは、重大なデータ侵害につながる可能性があります。共有責任モデルでは、組織が必要な制限を実装できない場合もあり、不正アクセスやデータ流出のリスクを高めます。
例えば、ChatGPTはプラグインがサードパーティ製サービスと統合することを許可していますが、信頼できないプラグインが誤って企業インスタンスに接続された場合、これは主要なデータ漏洩源となる可能性があります。同様に、不適切なアクセス制御設定は、不正なユーザーがAIシステムを通じて機密データにアクセスする原因となる可能性があります。
レッドチームは新しい概念ではありませんが、LLMはブラックボックスとして機能し、その出力は予測できないため、AIスタックのすべての層で特に重要です。例えば、Anthropicの研究では、LLMがモデルの重みに隠された攻撃が予期せず表面化する可能性のあるスリーパーエージェントになり得ることが示されました。
このリスクを軽減するために、組織はサードパーティ製サービスの統合を制限し、権限を制限し、AI環境の設定を定期的にレビューすることで、AI設定のベストプラクティスに従うべきです。Skyhigh SecurityのAIアプリケーションの安全な利用ソリューションは、AIシステムが適切に設定され、保護されていることを保証するためのツールとベストプラクティスを提供します。
レイヤー1におけるAIセキュリティの強化
上記のセキュリティリスクは、異なるユースケースに基づいて対処する必要があります。LLMの社内向け公開展開の場合、企業はすでにすべてのSaaSアプリケーションとサービスに対して、検出、アクセス制御、データ保護のためにSecure Service Edge (SSEフォワードプロキシ) を使用しているため、これはSaaS AIアプリケーションへの制御を拡張するための論理的なプラットフォームとなります。一方、プライベートインフラストラクチャへの展開の場合、SSEリバースプロキシ(またはLLM API経由)とAIガードレールを組み合わせたLLMファイアウォールが、ゼロトラストセキュリティを実現するための適切なパラダイムとなるでしょう。展開モデルに関わらず、継続的な検出、レッドチーム、および設定監査も重要になります。

上図は、企業内または信頼できるユーザーおよびデバイスからのLLM利用を保護するための包括的なアーキテクチャを示しています。顧客および管理されていないデバイスに対する同様のアプローチは、主にリバースプロキシのみを含む下部のフローに焦点を当てます。
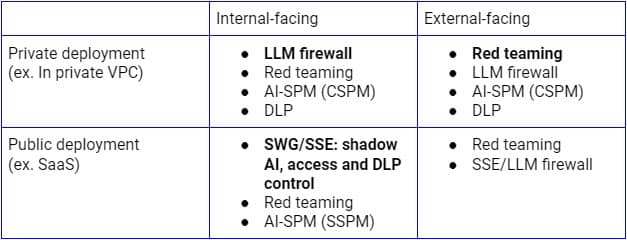
Foundational AIの展開の初期段階でこれらのセキュリティリスクに対処することは、AIシステムの成功とセキュリティを確保するために不可欠です。この基盤層におけるAIセキュリティを強化するために、組織は以下を行うべきです。
- 定期的な監査を実施する:AIシステムがプロンプトインジェクションの脆弱性、設定ミス、およびデータ処理の問題について定期的にレビューされることを確認します。
- 入力検証を実装する:プロンプトと入力を検証するための堅牢なメカニズムを使用し、プロンプトエンジニアリング攻撃のリスクを軽減します。
- データ保護対策を採用する:AIとのやり取り中のデータ漏洩のリスクを最小限に抑えるため、強固なデータガバナンスフレームワークを確立します。
- AI環境を保護する:AIシステムの設定に関するベストプラクティスに従い、特にサードパーティ製プラグインやサービスを統合する際には注意します。
今後の展望:基礎からAIを保護する
Foundational AIは多くの高度なAIアプリケーションの基盤となりますが、プロンプトエンジニアリング攻撃、データ漏洩、設定ミスなど、重大なセキュリティリスクももたらします。AIが業界全体のイノベーションを推進する上で極めて重要な役割を果たし続ける中、企業はこの基盤層から始めて、最初からセキュリティを優先する必要があります。
シリーズの次回のブログでは、意思決定を支援し、多種多様なタスクを自動化できるAIコパイロット、バーチャルアシスタント、生産性向上ツールといったレイヤー2に関連するセキュリティのニーズと機会を探求します。AIアプリケーションの保護とリスク軽減についてさらに詳しく知るには、Skyhigh AIソリューションをご覧ください。
このシリーズのその他のブログ:
- パート1 – AIセキュリティ:顧客のニーズと機会
- パート2 – 基盤AI: セキュリティ課題を伴う重要な層
- パート3 – AI Copilotにおけるセキュリティリスクと課題



トレンドブログ
Product Updates Q2 2026: Simplified Security Across Web, Cloud, Data, and AI
Thyaga Vasudevan July 21, 2026
Modernizing Your Symantec Edge Secure Web Gateway With Skyhigh Hybrid SSE Mesh
Sarang Warudkar July 15, 2026
Skyhigh Security CSA STARレベル2認証Skyhigh Security 、独立系クラウドセキュリティ保証の水準を引き上げる
スチュアート・ベイリス、サラン・ワルドカー 2026年6月25日
Skyhigh Security 、2026年におけるIRAP評価を「PROTECTED」レベルでSkyhigh Security
サラン・ワルドカー、スチュアート・ベイリス 2026年5月21日