ทรัพยากร
การชั่งน้ำหนักข้อดีและความเสี่ยงของระบบ AI Autopilot
โดย Sekhar Sarukkai - Cybersecurity@UC Berkeley
25 ตุลาคม 2567 6 อ่านนาที

ใน บล็อกก่อนหน้านี้ เราได้สำรวจความท้าทายด้านความปลอดภัยที่เกี่ยวข้องกับ AI Copilots ซึ่งเป็นระบบที่ช่วยในการทำงานและการตัดสินใจแต่ยังคงต้องอาศัยอินพุตของมนุษย์ เราได้พูดถึงความเสี่ยงต่างๆ เช่น การวางยาพิษข้อมูล การใช้สิทธิ์อนุญาตในทางที่ผิด และ AI Copilots ที่ไม่น่าเชื่อถือ เมื่อระบบ AI ก้าวหน้าขึ้นพร้อมกับการเกิดขึ้นของกรอบงานตัวแทน AI เช่น LangGraph และ AutoGen ความเสี่ยงด้านความปลอดภัยก็เพิ่มมากขึ้น โดยเฉพาะอย่างยิ่งกับ AI Autopilots ซึ่งเป็นชั้นถัดไปของการพัฒนา AI
ในบล็อกสุดท้ายของซีรีส์นี้ เราจะเน้นที่ Layer 3: AI Autopilots ซึ่งเป็นระบบตัวแทนอัตโนมัติที่สามารถทำงานต่างๆ ได้โดยไม่ต้องมีการแทรกแซงจากมนุษย์เลย แม้ว่าระบบเหล่านี้จะมีศักยภาพมหาศาลในการทำงานอัตโนมัติและประสิทธิภาพการทำงาน แต่ AI Autopilots ก็ยังก่อให้เกิดความเสี่ยงด้านความปลอดภัยที่สำคัญที่องค์กรต่างๆ จะต้องจัดการเพื่อให้มั่นใจว่าจะสามารถใช้งานได้อย่างปลอดภัย
ประโยชน์และความเสี่ยงของ AI Autopilots
ระบบตัวแทนสร้างขึ้นจากโมเดลภาษาขนาดใหญ่ (LLM) และการสร้างเสริมการเรียกค้น (RAG) ระบบเหล่านี้เพิ่มความสามารถในการดำเนินการผ่านการตรวจสอบภายใน การวิเคราะห์งาน การเรียกใช้ฟังก์ชัน และการใช้ประโยชน์จากตัวแทนหรือมนุษย์คนอื่นเพื่อทำงานให้เสร็จสมบูรณ์ ซึ่งต้องใช้กรอบงานในการระบุและตรวจสอบตัวตนของตัวแทนและมนุษย์ รวมถึงเพื่อให้แน่ใจว่าการดำเนินการและผลลัพธ์นั้นน่าเชื่อถือ มุมมองที่เรียบง่ายของ LLM ที่โต้ตอบกับมนุษย์ในเลเยอร์ 1 จะถูกแทนที่ด้วยกลุ่มตัวแทนที่สร้างขึ้นแบบไดนามิกที่ทำงานร่วมกันเพื่อทำงานให้เสร็จสมบูรณ์ ซึ่งเพิ่มความกังวลด้านความปลอดภัยหลายเท่า ในความเป็นจริง การเปิดตัว Claude จาก Anthropic เวอร์ชันล่าสุดเป็น ฟีเจอร์ที่อนุญาตให้ AI ใช้คอมพิวเตอร์ แทนคุณ ทำให้ AI สามารถใช้เครื่องมือที่จำเป็นในการทำงานให้เสร็จสมบูรณ์โดยอัตโนมัติ ซึ่งถือเป็นประโยชน์ต่อผู้ใช้และเป็นความท้าทายต่อเจ้าหน้าที่ด้านความปลอดภัย

1. การกระทำที่เป็นอิสระจากการก่ออาชญากรรมหรือการต่อต้าน
ระบบ AI Autopilots สามารถดำเนินการงานต่างๆ ได้อย่างอิสระตามวัตถุประสงค์ที่กำหนดไว้ล่วงหน้า อย่างไรก็ตาม ระบบอัตโนมัตินี้เปิดโอกาสให้เกิดความเสี่ยงในการดำเนินการที่ไม่ถูกต้อง ซึ่งระบบอัตโนมัติอาจเบี่ยงเบนไปจากพฤติกรรมที่ตั้งใจไว้เนื่องจากข้อบกพร่องในการเขียนโปรแกรมหรือการจัดการที่เป็นปฏิปักษ์ ระบบ AI ที่ไม่ถูกต้องอาจก่อให้เกิดผลลัพธ์ที่ไม่ได้ตั้งใจหรือเป็นอันตราย ตั้งแต่การละเมิดข้อมูลไปจนถึงความล้มเหลวในการดำเนินงาน
ตัวอย่างเช่น ระบบ AI Autopilot ที่จัดการระบบโครงสร้างพื้นฐานที่สำคัญอาจปิดระบบไฟฟ้าโดยไม่ได้ตั้งใจหรือปิดใช้งานฟังก์ชันที่จำเป็นเนื่องจากข้อมูลอินพุตที่ตีความไม่ถูกต้องหรือการควบคุมดูแลโปรแกรม เมื่อเริ่มดำเนินการแล้ว การกระทำที่ไม่เหมาะสมเหล่านี้อาจหยุดได้ยากหากไม่มีการแทรกแซงทันที
การโจมตีแบบต่อต้านเป็น ภัยคุกคามร้ายแรงต่อระบบ AI Autopilot โดยเฉพาะในอุตสาหกรรมที่การตัดสินใจแบบอัตโนมัติอาจส่งผลร้ายแรง ผู้โจมตีสามารถบิดเบือนข้อมูลอินพุตหรือสภาพแวดล้อมอย่างแนบเนียนเพื่อหลอกให้โมเดล AI ตัดสินใจผิดพลาด การโจมตีแบบต่อต้านมักออกแบบมาเพื่อไม่ให้ถูกตรวจจับ โดยใช้ประโยชน์จากช่องโหว่ในกระบวนการตัดสินใจของระบบ AI
ตัวอย่างเช่น โดรนไร้คนขับอาจถูกหลอกล่อให้เปลี่ยนเส้นทางการบินโดยผู้โจมตีที่แอบเปลี่ยนแปลงสภาพแวดล้อม (ตัวอย่าง: วางวัตถุในเส้นทางของโดรนเพื่อรบกวนเซ็นเซอร์) ในทำนองเดียวกัน ยานยนต์ไร้คนขับอาจถูกหลอกล่อให้หยุดหรือเปลี่ยนเส้นทางเนื่องจากการเปลี่ยนแปลงเล็กน้อยที่มองไม่เห็นของป้ายจราจรหรือเครื่องหมายบนถนน
เคล็ดลับการบรรเทาผลกระทบ : ดำเนินการตรวจสอบแบบเรียลไทม์และวิเคราะห์พฤติกรรมเพื่อตรวจจับการเบี่ยงเบนใดๆ จากพฤติกรรม AI ที่คาดหวังไว้ ควรสร้างกลไกป้องกันความล้มเหลวเพื่อหยุดระบบอัตโนมัติทันทีหากระบบเริ่มดำเนินการที่ไม่ได้รับอนุญาต เพื่อป้องกันการโจมตีจากฝ่ายตรงข้าม องค์กรควรใช้เทคนิคการตรวจสอบอินพุตที่แข็งแกร่งและการทดสอบโมเดล AI บ่อยครั้ง การฝึกอบรมเชิงต่อต้าน ซึ่งโมเดล AI ได้รับการฝึกอบรมให้จดจำและต้านทานอินพุตที่บิดเบือน ถือเป็นสิ่งสำคัญเพื่อให้แน่ใจว่า AI Autopilots สามารถต้านทานภัยคุกคามเหล่านี้ได้
2. การขาดความโปร่งใสและความเสี่ยงด้านจริยธรรม
เมื่อระบบอัตโนมัติของ AI ทำงานโดยปราศจากการควบคุมดูแลโดยตรงจากมนุษย์ ปัญหาเรื่องความรับผิดชอบจึงมีความซับซ้อนมากขึ้น หากระบบอัตโนมัติตัดสินใจผิดพลาดจนส่งผลให้เกิดการสูญเสียทางการเงิน การหยุดชะงักในการดำเนินงาน หรือปัญหาทางกฎหมาย การกำหนดความรับผิดชอบอาจเป็นเรื่องยาก การขาดความรับผิดชอบที่ชัดเจนนี้ก่อให้เกิดคำถามด้านจริยธรรมที่สำคัญ โดยเฉพาะในอุตสาหกรรมที่ความปลอดภัยและความยุติธรรมเป็นสิ่งสำคัญที่สุด
ความเสี่ยงด้านจริยธรรมยังเกิดขึ้นเมื่อระบบเหล่านี้ให้ความสำคัญกับประสิทธิภาพมากกว่าความยุติธรรมหรือความปลอดภัย ซึ่งอาจนำไปสู่ผลลัพธ์หรือการตัดสินใจที่เลือกปฏิบัติซึ่งขัดแย้งกับค่านิยมขององค์กร ตัวอย่างเช่น ระบบ AI Autopilot ในระบบการจ้างงานอาจให้ความสำคัญกับมาตรการประหยัดต้นทุนมากกว่าความหลากหลายโดยไม่ได้ตั้งใจ ส่งผลให้เกิดแนวทางการจ้างงานที่ไม่เป็นกลาง
เคล็ดลับการบรรเทาผลกระทบ : จัดทำกรอบความรับผิดชอบและคณะกรรมการกำกับดูแลด้านจริยธรรมเพื่อให้แน่ใจว่า AI Autopilots สอดคล้องกับค่านิยมขององค์กร ควรมีการตรวจสอบและทบทวนด้านจริยธรรมเป็นประจำเพื่อติดตามการตัดสินใจด้าน AI และควรจัดทำโครงสร้างความรับผิดชอบที่ชัดเจนเพื่อจัดการกับปัญหาทางกฎหมายที่อาจเกิดขึ้นจากการดำเนินการโดยอิสระ
3. การระบุตัวตน การรับรองความถูกต้องและการอนุญาตของตัวแทน
ปัญหาพื้นฐานอย่างหนึ่งของระบบมัลติเอเจนต์คือความจำเป็นในการพิสูจน์ตัวตนของเอเจนต์และอนุมัติคำขอของเอเจนต์ไคลเอนต์ ซึ่งอาจกลายเป็นความท้าทายหากเอเจนต์ปลอมตัวเป็นตัวแทนอื่น หรือหากไม่สามารถยืนยันตัวตนของเอเจนต์ที่ร้องขอได้อย่างชัดเจน ในโลกอนาคตที่เอเจนต์ที่มีสิทธิ์ขั้นสูงสื่อสารกันเองและทำงานให้เสร็จ ความเสียหายที่เกิดขึ้นอาจเกิดขึ้นทันทีและตรวจจับได้ยาก เว้นแต่จะบังคับใช้การควบคุมการอนุญาตแบบละเอียดอย่างเข้มงวด
เนื่องจากตัวแทนเฉพาะทางขยายตัวและทำงานร่วมกัน การตรวจสอบตัวตนและข้อมูลประจำตัวของตัวแทนจึงมีความสำคัญเพิ่มมากขึ้น เพื่อให้แน่ใจว่าไม่มีตัวแทนที่ไม่ได้รับอนุญาตเข้ามาแทรกซึมในองค์กร ในทำนองเดียวกัน แผนการอนุญาตต้องคำนึงถึงการใช้งานอัตโนมัติตามการจำแนกประเภท บทบาท และฟังก์ชันของตัวแทนเพื่อให้ทำงานสำเร็จลุล่วง
เคล็ดลับการบรรเทาผลกระทบ : เพื่อป้องกันการโจมตีจากฝ่ายตรงข้าม องค์กรต่างๆ ควรใช้เทคนิคการตรวจสอบข้อมูลอินพุตที่แข็งแกร่งและการทดสอบโมเดล AI บ่อยครั้ง การฝึกอบรมเชิงต่อต้าน ซึ่งโมเดล AI จะได้รับการฝึกอบรมให้จดจำและต้านทานข้อมูลอินพุตที่บิดเบือน ถือเป็นสิ่งสำคัญเพื่อให้แน่ใจว่า AI Autopilots สามารถต้านทานภัยคุกคามเหล่านี้ได้
4. การพึ่งพาอำนาจปกครองตนเองมากเกินไป
เนื่องจากองค์กรต่างๆ นำระบบ AI Autopilot มาใช้มากขึ้น จึงมีความเสี่ยงที่ระบบจะพึ่งพาระบบอัตโนมัติมากเกินไป ซึ่งเกิดขึ้นเมื่อการตัดสินใจที่สำคัญถูกปล่อยให้ระบบอัตโนมัติดูแลโดยปราศจากการควบคุมดูแลของมนุษย์ แม้ว่าระบบ AI Autopilot จะออกแบบมาเพื่อจัดการกับงานประจำวัน แต่การเอาอินพุตของมนุษย์ออกจากการตัดสินใจที่สำคัญอาจทำให้เกิดจุดบอดในการทำงานและเกิดข้อผิดพลาดที่ตรวจไม่พบ ซึ่งแสดงออกมาผ่านการดำเนินการ เรียกใช้เครื่องมืออัตโนมัติ ที่ดำเนินการโดยตัวแทน ซึ่งเป็นปัญหาเนื่องจากในหลายกรณี ตัวแทนเหล่านี้มีสิทธิ์พิเศษในการดำเนินการเหล่านี้ และยิ่งเป็นปัญหาใหญ่ขึ้นเมื่อตัวแทนเป็นอิสระ โดยสามารถใช้ การแฮ็กแบบรวดเร็ว เพื่อบังคับให้ดำเนินการที่ผิดกฎหมายโดยที่ผู้ใช้ไม่ทราบ นอกจากนี้ ในระบบที่มีตัวแทนหลายราย ปัญหาของ ตัวแทนรองที่สับสน คือปัญหาการดำเนินการที่อาจเพิ่มสิทธิ์พิเศษอย่างแอบๆ
การพึ่งพามากเกินไปอาจกลายเป็นอันตรายอย่างยิ่งในสภาพแวดล้อมที่มีการเปลี่ยนแปลงอย่างรวดเร็วซึ่งยังคงต้องใช้การตัดสินใจของมนุษย์แบบเรียลไทม์ ตัวอย่างเช่น ระบบ AI Autopilot ที่จัดการความปลอดภัยทางไซเบอร์อาจมองข้ามความแตกต่างของภัยคุกคามที่เปลี่ยนแปลงอย่างรวดเร็ว โดยพึ่งพาการตอบสนองตามโปรแกรมแทนที่จะปรับตัวตามการเปลี่ยนแปลงที่ไม่คาดคิด
เคล็ดลับการบรรเทาผลกระทบ : ควรบำรุงรักษา ระบบ Human-in-the-loop (HITL) เพื่อให้แน่ใจว่าผู้ปฏิบัติงานที่เป็นมนุษย์ยังคงควบคุมการตัดสินใจที่สำคัญได้ แนวทางแบบผสมผสานนี้ช่วยให้ AI Autopilots สามารถจัดการงานประจำได้ในขณะที่มนุษย์ดูแลและตรวจสอบการตัดสินใจที่สำคัญ องค์กรต่างๆ ควรประเมินเป็นประจำว่าเมื่อใดและที่ใดจึงจำเป็นต้องให้มนุษย์เข้ามาแทรกแซง เพื่อป้องกันการพึ่งพาระบบ AI มากเกินไป
5. เอกลักษณ์ทางกฎหมายของมนุษย์และความไว้วางใจ
ระบบอัตโนมัติของ AI ทำงานโดยอิงตามวัตถุประสงค์ที่กำหนดไว้ล่วงหน้าและทำงานร่วมกับมนุษย์ อย่างไรก็ตาม ความร่วมมือนี้ยังต้องการให้ตัวแทนตรวจสอบตัวตนของมนุษย์ที่พวกเขากำลังทำงานร่วมกันด้วย เนื่องจากการโต้ตอบเหล่านี้ไม่ได้เกิดขึ้นกับบุคคลที่ผ่านการรับรองโดยใช้เครื่องมือแจ้งเตือนเสมอ ลองพิจารณากรณีการหลอกลวง Deepfake ที่พนักงานฝ่ายการเงินในฮ่องกงจ่ายเงิน 25 ล้านดอลลาร์โดยสันนิษฐานว่า CFO เวอร์ชัน Deepfake ในการประชุมทางเว็บเป็น CFO ตัวจริง เหตุการณ์นี้เน้นย้ำถึงความเสี่ยงที่เพิ่มมากขึ้นของตัวแทนที่สามารถปลอมตัวเป็นมนุษย์ โดยเฉพาะอย่างยิ่งเมื่อการปลอมตัวเป็นมนุษย์ทำได้ง่ายขึ้นด้วยโมเดลมัลติโหมดล่าสุด OpenAI เตือนเมื่อไม่นานนี้ว่า ตัวอย่างเสียง 15 วินาทีก็เพียงพอ ที่จะปลอมตัวเป็นเสียงของมนุษย์ได้ วิดีโอ Deepfake ตามมาไม่ไกล ดังที่เห็นได้จากกรณีในฮ่องกง
นอกจากนี้ ในบางกรณี การแบ่งปันความลับที่ได้รับมอบหมายระหว่างมนุษย์และตัวแทนถือเป็นสิ่งสำคัญในการดำเนินการภารกิจให้สำเร็จลุล่วง เช่น ผ่านกระเป๋าเงิน (สำหรับตัวแทนส่วนบุคคล) ในบริบทขององค์กร ตัวแทนทางการเงินอาจจำเป็นต้องตรวจสอบตัวตนทางกฎหมายของมนุษย์และความสัมพันธ์ของพวกเขา ในปัจจุบัน ไม่มีวิธีการมาตรฐานใด ๆ สำหรับตัวแทนในการดำเนินการดังกล่าว หากไม่มีวิธีการเหล่านี้ ตัวแทนจะไม่สามารถทำงานร่วมกับมนุษย์ได้ในโลกที่มนุษย์จะกลายเป็นผู้ช่วยนักบินมากขึ้นเรื่อยๆ
ปัญหานี้จะยิ่งเป็นอันตรายโดยเฉพาะอย่างยิ่งเมื่อระบบ AI Autopilot ตัดสินใจโดยไม่ได้ตั้งใจโดยอิงจากผู้กระทำผิดที่แอบอ้างตัวเป็นผู้ร่วมงานที่เป็นมนุษย์ หากไม่มีวิธีการที่ชัดเจนในการพิสูจน์ตัวตนทางดิจิทัลของมนุษย์ ตัวแทนอาจกระทำการในลักษณะที่ขัดแย้งกับเป้าหมายทางธุรกิจที่กว้างขึ้น เช่น ความปลอดภัย การปฏิบัติตามข้อกำหนด หรือการพิจารณาทางจริยธรรม
เคล็ดลับการบรรเทาผลกระทบ : การตรวจสอบข้อมูลประจำตัวของผู้ใช้และตัวแทนที่เกี่ยวข้องกับการดำเนินการงาน AI Autopilots อย่างสม่ำเสมอถือเป็นสิ่งสำคัญ องค์กรควรใช้อัลกอริทึมที่ปรับเปลี่ยนได้และกลไกการตอบรับแบบเรียลไทม์เพื่อให้แน่ใจว่าระบบ AI ยังคงสอดคล้องกับผู้ใช้ที่เปลี่ยนแปลงไปและข้อกำหนดด้านกฎระเบียบ โดยการปรับวัตถุประสงค์ตามความจำเป็น ธุรกิจสามารถป้องกันไม่ให้เป้าหมายที่ไม่สอดคล้องกันนำไปสู่ผลลัพธ์ที่ไม่พึงประสงค์ได้
การรักษาความปลอดภัยระบบ AI Autopilots: แนวทางปฏิบัติที่ดีที่สุด
นอกเหนือจากการควบคุมความปลอดภัยที่หารือกันในสองชั้นก่อนหน้านี้ ซึ่งรวมถึงการป้องกัน LLM สำหรับ LLM และการควบคุมข้อมูลสำหรับ Copilot แล้ว เลเยอร์ตัวแทนยังจำเป็นต้องมีการแนะนำบทบาทที่ขยายออกสำหรับการจัดการข้อมูลประจำตัวและการเข้าถึง (IAM) เช่นเดียวกับการดำเนินงานที่เชื่อถือได้
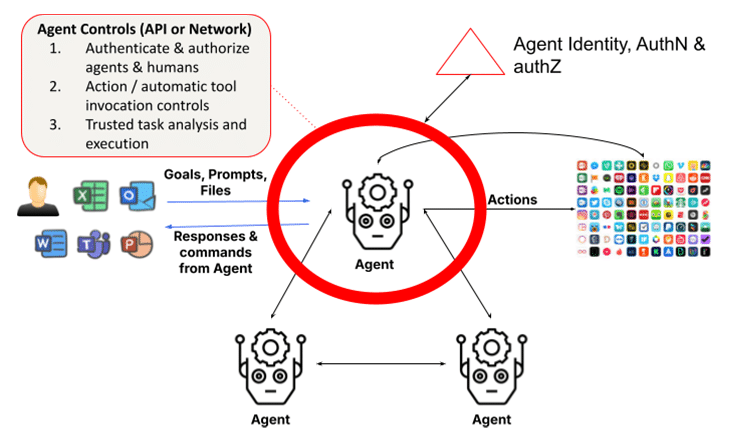
เพื่อลดความเสี่ยงจาก AI Autopilots องค์กรต่างๆ ควรนำกลยุทธ์ด้านความปลอดภัยที่ครอบคลุมมาใช้ ซึ่งรวมถึง:
- การตรวจสอบอย่างต่อเนื่อง: นำการวิเคราะห์พฤติกรรมแบบเรียลไทม์มาใช้เพื่อตรวจจับความผิดปกติและการกระทำที่ไม่ได้รับอนุญาต
- การกำกับดูแลอย่างมีจริยธรรม: จัดตั้งคณะกรรมการจริยธรรมและกรอบความรับผิดชอบเพื่อให้แน่ใจว่าระบบ AI สอดคล้องกับค่านิยมขององค์กรและข้อกำหนดทางกฎหมาย
- การป้องกันตนเอง: ใช้การฝึกอบรมการต่อต้านและการตรวจสอบข้อมูลที่แข็งแกร่งเพื่อป้องกันการจัดการ
- การกำกับดูแลของมนุษย์: บำรุงรักษาระบบ HITL เพื่อรักษาการกำกับดูแลการตัดสินใจที่สำคัญที่ทำโดย AI
โดยการนำแนวทางปฏิบัติที่ดีที่สุดเหล่านี้ไปใช้ องค์กรต่างๆ จะสามารถมั่นใจได้ว่า AI Autopilots ทำงานได้อย่างปลอดภัยและสอดคล้องกับเป้าหมายทางธุรกิจ
เส้นทางข้างหน้า: การรักษาความปลอดภัย AI อัตโนมัติ
AI Autopilots สัญญาว่าจะปฏิวัติอุตสาหกรรมต่างๆ ด้วยการทำให้กระบวนการที่ซับซ้อนกลายเป็นระบบอัตโนมัติ แต่ก็ก่อให้เกิดความเสี่ยงด้านความปลอดภัยที่สำคัญด้วยเช่นกัน องค์กรต่างๆ ต้องเฝ้าระวังในการจัดการความเสี่ยงเหล่านี้ ตั้งแต่การกระทำที่ผิดกฎหมายไปจนถึงการหลอกลวง เนื่องจาก AI ยังคงพัฒนาอย่างต่อเนื่อง จึงมีความสำคัญอย่างยิ่งที่จะต้องให้ความสำคัญกับความปลอดภัยในทุกขั้นตอน เพื่อให้แน่ใจว่าระบบเหล่านี้ทำงานได้อย่างปลอดภัยและสอดคล้องกับเป้าหมายขององค์กร
หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับการรักษาความปลอดภัยแอปพลิเคชัน AI ของคุณ: อ่านข้อมูลสรุปโซลูชันของเรา
บล็อกอื่นๆ ในซีรี่ส์นี้:
- ส่วนที่ 1 – ความปลอดภัยของ AI: ความต้องการและโอกาสของลูกค้า
- ส่วนที่ 2 – AI พื้นฐาน: ชั้นสำคัญที่มีความท้าทายด้านความปลอดภัย
- ส่วนที่ 3 – ความเสี่ยงด้านความปลอดภัยและความท้าทายกับ AI Copilots
- ตอนที่ 4 – การชั่งน้ำหนักข้อดีและความเสี่ยงของระบบ AI Autopilot
เนื้อหาที่เกี่ยวข้อง



บล็อกที่กำลังได้รับความนิยม
Product Updates Q2 2026: Simplified Security Across Web, Cloud, Data, and AI
Thyaga Vasudevan July 21, 2026
Modernizing Your Symantec Edge Secure Web Gateway With Skyhigh Hybrid SSE Mesh
Sarang Warudkar July 15, 2026
Skyhigh Security CSA STAR ระดับ 2 ซึ่งช่วยยกระดับมาตรฐานการรับรองความปลอดภัยบนคลาวด์แบบอิสระ
สจวร์ต เบย์ลิส และ ซารัง วารุดการ์ 25 มิถุนายน 2026
วิธีการที่แตกต่าง: ทำไมคำตอบสำหรับปัญหาความปลอดภัยของเบราว์เซอร์จึงไม่ใช่เบราว์เซอร์ใหม่
Sarang Warudkar 17 มิถุนายน 2026
Skyhigh Security การประเมิน IRAP ที่ระดับ PROTECTED สำหรับปี 2026
สารัง วรุธกฤา และ สจวร์ต เบลลิส 21 พฤษภาคม 2026