संसाधन
एआई ऑटोपायलट के लाभ और जोखिम का मूल्यांकन
शेखर सरुक्काई द्वारा - साइबरसिक्यूरिटी@यूसी बर्कले
25 अक्टूबर, 2024 6 मिनट पढ़ें

पिछले ब्लॉग में, हमने AI Copilots से जुड़ी सुरक्षा चुनौतियों का पता लगाया, जो सिस्टम कार्यों और निर्णयों में सहायता करते हैं लेकिन फिर भी मानव इनपुट पर निर्भर करते हैं। हमने डेटा पॉइज़निंग, अनुमतियों के दुरुपयोग और दुष्ट AI Copilots जैसे जोखिमों पर चर्चा की। जैसे-जैसे AI सिस्टम LangGraph और AutoGen जैसे AI एजेंटिक फ्रेमवर्क के उद्भव के साथ आगे बढ़ते हैं, सुरक्षा जोखिमों की संभावना बढ़ जाती है - विशेष रूप से AI ऑटोपायलट के साथ, AI विकास की अगली परत।
हमारी श्रृंखला के इस अंतिम ब्लॉग में, हम लेयर 3 पर ध्यान केंद्रित करेंगे: AI ऑटोपायलट - स्वायत्त एजेंटिक सिस्टम जो बहुत कम या बिना किसी मानवीय हस्तक्षेप के कार्य कर सकते हैं। जबकि वे कार्य स्वचालन और परिचालन दक्षता के लिए जबरदस्त क्षमता प्रदान करते हैं, AI ऑटोपायलट महत्वपूर्ण सुरक्षा जोखिम भी पेश करते हैं जिन्हें संगठनों को सुरक्षित तैनाती सुनिश्चित करने के लिए संबोधित करना चाहिए।
एआई ऑटोपायलट के लाभ और जोखिम
एजेंटिक सिस्टम बड़े भाषा मॉडल (LLM) और पुनर्प्राप्ति-संवर्धित पीढ़ी (RAG) पर आधारित होते हैं। वे आत्मनिरीक्षण, कार्य विश्लेषण, फ़ंक्शन कॉलिंग और अपने कार्यों को पूरा करने के लिए अन्य एजेंटों या मनुष्यों का लाभ उठाने के माध्यम से कार्रवाई करने की क्षमता जोड़ते हैं। इसके लिए एजेंटों को एजेंट और मानव पहचान की पहचान करने और उन्हें मान्य करने के साथ-साथ यह सुनिश्चित करने के लिए एक ढांचे का उपयोग करने की आवश्यकता होती है कि क्रियाएं और परिणाम विश्वसनीय हैं। लेयर 1 में एक मानव के साथ बातचीत करने वाले LLM के सरल दृश्य को एजेंटों के गतिशील रूप से गठित समूहों के संग्रह द्वारा प्रतिस्थापित किया जाता है जो एक कार्य को पूरा करने के लिए एक साथ काम करते हैं, जिससे सुरक्षा संबंधी चिंताएँ कई गुना बढ़ जाती हैं। वास्तव में, एंथ्रोपिक से क्लाउड की सबसे हालिया रिलीज़ एक ऐसी सुविधा है जो AI को आपकी ओर से कंप्यूटर का उपयोग करने की अनुमति देती है , जिससे AI को स्वायत्त रूप से कार्य पूरा करने के लिए आवश्यक उपकरणों का उपयोग करने में सक्षम बनाता है - उपयोगकर्ताओं के लिए एक वरदान और सुरक्षा लोगों के लिए एक चुनौती।

1. दुष्ट या प्रतिकूल स्वायत्त क्रियाएँ
एआई ऑटोपायलट पूर्वनिर्धारित उद्देश्यों के आधार पर स्वतंत्र रूप से कार्य निष्पादित करने में सक्षम हैं। हालाँकि, यह स्वायत्तता दुष्ट कार्यों के जोखिम को खोलती है, जहाँ एक ऑटोपायलट प्रोग्रामिंग दोषों या प्रतिकूल हेरफेर के कारण इच्छित व्यवहार से विचलित हो सकता है। दुष्ट एआई सिस्टम डेटा उल्लंघनों से लेकर परिचालन विफलताओं तक अनपेक्षित या हानिकारक परिणाम पैदा कर सकते हैं ।
उदाहरण के लिए, महत्वपूर्ण बुनियादी ढाँचा प्रणालियों का प्रबंधन करने वाला एक AI ऑटोपायलट गलत तरीके से इनपुट डेटा या प्रोग्रामिंग ओवरसाइट के कारण गलती से पावर ग्रिड को बंद कर सकता है या आवश्यक कार्यों को अक्षम कर सकता है। एक बार गति में आने के बाद, इन दुष्ट क्रियाओं को तत्काल हस्तक्षेप के बिना रोकना मुश्किल हो सकता है।
प्रतिकूल हमले एआई ऑटोपायलट के लिए एक गंभीर खतरा पैदा करते हैं, खासकर उन उद्योगों में जहां स्वायत्त निर्णयों के गंभीर परिणाम हो सकते हैं। हमलावर एआई मॉडल को गलत निर्णय लेने के लिए धोखा देने के लिए इनपुट डेटा या पर्यावरण में सूक्ष्मता से हेरफेर कर सकते हैं। इन प्रतिकूल हमलों को अक्सर बिना पता लगाए जाने के लिए डिज़ाइन किया जाता है, जो एआई सिस्टम की निर्णय लेने की प्रक्रिया में कमजोरियों का फायदा उठाते हैं।
उदाहरण के लिए, हमलावरों द्वारा पर्यावरण में सूक्ष्म रूप से परिवर्तन करके एक स्वायत्त ड्रोन को अपने उड़ान पथ को बदलने के लिए प्रेरित किया जा सकता है (उदाहरण: ड्रोन के मार्ग में ऐसी वस्तुएँ रखना जो उसके सेंसर को बाधित करती हैं)। इसी तरह, सड़क के संकेतों या चिह्नों में छोटे, अगोचर परिवर्तनों के कारण स्वायत्त वाहनों को रोकने या रास्ते से भटकाने के लिए प्रेरित किया जा सकता है।
शमन सुझाव : अपेक्षित AI व्यवहार से किसी भी विचलन का पता लगाने के लिए वास्तविक समय की निगरानी और व्यवहार विश्लेषण लागू करें। यदि स्वायत्त सिस्टम अनधिकृत कार्य करना शुरू करते हैं, तो उन्हें तुरंत रोकने के लिए विफलता-सुरक्षित तंत्र स्थापित किए जाने चाहिए। प्रतिकूल हमलों से बचाव के लिए, संगठनों को मजबूत इनपुट सत्यापन तकनीकों और AI मॉडल के लगातार परीक्षण को लागू करना चाहिए। प्रतिकूल प्रशिक्षण, जहां AI मॉडल को हेरफेर करने वाले इनपुट को पहचानने और उनका विरोध करने के लिए प्रशिक्षित किया जाता है, यह सुनिश्चित करने के लिए आवश्यक है कि AI ऑटोपायलट इन खतरों का सामना कर सकें।
2. पारदर्शिता का अभाव और नैतिक जोखिम
एआई ऑटोपायलट के बिना प्रत्यक्ष मानवीय निगरानी के संचालन के कारण जवाबदेही के मुद्दे और भी जटिल हो जाते हैं । यदि कोई स्वायत्त प्रणाली कोई गलत निर्णय लेती है जिसके परिणामस्वरूप वित्तीय हानि, परिचालन में व्यवधान या कानूनी जटिलताएँ होती हैं, तो जिम्मेदारी निर्धारित करना मुश्किल हो सकता है। स्पष्ट जवाबदेही की यह कमी महत्वपूर्ण नैतिक प्रश्न उठाती है, खासकर उन उद्योगों में जहाँ सुरक्षा और निष्पक्षता सर्वोपरि है।
नैतिक जोखिम तब भी उत्पन्न होते हैं जब ये प्रणालियाँ निष्पक्षता या सुरक्षा पर दक्षता को प्राथमिकता देती हैं, जिससे संभावित रूप से भेदभावपूर्ण परिणाम या ऐसे निर्णय सामने आते हैं जो संगठनात्मक मूल्यों के साथ टकराव करते हैं। उदाहरण के लिए, किसी भर्ती प्रणाली में एक AI ऑटोपायलट अनजाने में विविधता पर लागत-बचत उपायों को प्राथमिकता दे सकता है, जिसके परिणामस्वरूप पक्षपातपूर्ण भर्ती प्रथाएँ हो सकती हैं।
शमन सुझाव : एआई ऑटोपायलट को संगठनात्मक मूल्यों के साथ संरेखित करने के लिए जवाबदेही ढांचे और नैतिक निरीक्षण बोर्ड स्थापित करें। एआई निर्णय लेने की निगरानी के लिए नियमित ऑडिट और नैतिक समीक्षा की जानी चाहिए, और स्वायत्त कार्यों से उत्पन्न होने वाले संभावित कानूनी मुद्दों को संभालने के लिए स्पष्ट जवाबदेही संरचनाएं स्थापित की जानी चाहिए।
3. एजेंट की पहचान, प्रमाणीकरण और प्राधिकरण
मल्टी-एजेंट सिस्टम के साथ एक मूलभूत समस्या एजेंटों की पहचान को प्रमाणित करने और क्लाइंट एजेंट अनुरोधों को अधिकृत करने की आवश्यकता है। यह एक चुनौती बन सकता है यदि एजेंट अन्य एजेंटों के रूप में छद्मवेश कर सकते हैं या यदि अनुरोध करने वाले एजेंट की पहचान को दृढ़ता से सत्यापित नहीं किया जा सकता है। भविष्य की दुनिया में जहां एस्केलेटेड-प्रिविलेज एजेंट एक-दूसरे के साथ संवाद करते हैं और कार्यों को पूरा करते हैं, तब तक होने वाला नुकसान तात्कालिक और पता लगाना मुश्किल हो सकता है जब तक कि बारीक-बारीक प्राधिकरण नियंत्रणों को सख्ती से लागू नहीं किया जाता है।
जैसे-जैसे विशेषज्ञ एजेंट बढ़ते हैं और एक-दूसरे के साथ सहयोग करते हैं, एजेंटों की पहचान और उनकी साख का आधिकारिक सत्यापन करना बहुत ज़रूरी हो जाता है, ताकि यह सुनिश्चित किया जा सके कि उद्यमों में कोई दुष्ट एजेंट घुसपैठ न कर सके। इसी तरह, अनुमति योजनाओं को कार्य पूरा करने के लिए एजेंट वर्गीकरण-, भूमिका- और कार्य-आधारित स्वचालित उपयोग को ध्यान में रखना चाहिए।
शमन सुझाव : प्रतिकूल हमलों से बचाव के लिए, संगठनों को मजबूत इनपुट सत्यापन तकनीकों को लागू करना चाहिए और AI मॉडल का लगातार परीक्षण करना चाहिए। प्रतिकूल प्रशिक्षण, जहां AI मॉडल को हेरफेर करने वाले इनपुट को पहचानने और उनका विरोध करने के लिए प्रशिक्षित किया जाता है, यह सुनिश्चित करने के लिए आवश्यक है कि AI ऑटोपायलट इन खतरों का सामना कर सकें।
4. स्वायत्तता पर अत्यधिक निर्भरता
जैसे-जैसे संगठन तेजी से एआई ऑटोपायलट को अपना रहे हैं, स्वचालन पर अत्यधिक निर्भरता का जोखिम बढ़ रहा है। ऐसा तब होता है जब महत्वपूर्ण निर्णय पूरी तरह से मानव निरीक्षण के बिना स्वायत्त प्रणालियों पर छोड़ दिए जाते हैं। जबकि एआई ऑटोपायलट को नियमित कार्यों को संभालने के लिए डिज़ाइन किया गया है, महत्वपूर्ण निर्णयों से मानव इनपुट को हटाने से परिचालन संबंधी अंधे धब्बे और अनदेखी त्रुटियाँ हो सकती हैं। यह एजेंटों द्वारा की गई स्वचालित टूल इनवोकेशन कार्रवाई के माध्यम से प्रकट होता है। यह एक समस्या है क्योंकि, कई मामलों में, इन एजेंटों के पास इन कार्यों को करने के लिए उन्नत विशेषाधिकार हैं। और यह तब और भी बड़ा मुद्दा है जब एजेंट स्वायत्त होते हैं जहां उपयोगकर्ता की जानकारी के बिना नापाक कार्रवाई करने के लिए त्वरित इंजेक्शन हैकिंग का उपयोग किया जा सकता है। इसके अलावा, मल्टी-एजेंट सिस्टम में भ्रमित डिप्टी समस्या ऐसी कार्रवाइयों के साथ एक समस्या है जो चुपके से विशेषाधिकार बढ़ा सकती हैं।
अत्यधिक निर्भरता विशेष रूप से तेज़ गति वाले वातावरण में खतरनाक हो सकती है जहाँ वास्तविक समय के मानवीय निर्णय की अभी भी आवश्यकता होती है। उदाहरण के लिए, साइबर सुरक्षा का प्रबंधन करने वाला एक AI ऑटोपायलट तेजी से विकसित हो रहे खतरे की बारीकियों को नज़रअंदाज़ कर सकता है, अप्रत्याशित परिवर्तनों के साथ तालमेल बिठाने के बजाय अपने प्रोग्राम किए गए जवाबों पर निर्भर रह सकता है।
शमन सुझाव : मानव-इन-द-लूप (HITL) सिस्टम को बनाए रखा जाना चाहिए ताकि यह सुनिश्चित किया जा सके कि मानव ऑपरेटर महत्वपूर्ण निर्णयों पर नियंत्रण बनाए रखें। यह हाइब्रिड दृष्टिकोण AI ऑटोपायलट को नियमित कार्यों को संभालने की अनुमति देता है जबकि मनुष्य प्रमुख निर्णयों की देखरेख और सत्यापन करते हैं। संगठनों को नियमित रूप से मूल्यांकन करना चाहिए कि कब और कहाँ मानव हस्तक्षेप आवश्यक है ताकि AI सिस्टम पर अत्यधिक निर्भरता को रोका जा सके।
5. मानव कानूनी पहचान और विश्वास
AI ऑटोपायलट पूर्वनिर्धारित उद्देश्यों के आधार पर और मनुष्यों के सहयोग से काम करते हैं। हालाँकि, इस सहयोग के लिए एजेंटों को उन मानव संस्थाओं को सत्यापित करने की भी आवश्यकता होती है जिनके साथ वे सहयोग कर रहे हैं, क्योंकि ये बातचीत हमेशा किसी प्रमाणित व्यक्ति के साथ नहीं होती है जो प्रॉम्प्टिंग टूल का उपयोग करता है। डीपफेक घोटाले पर विचार करें, जहाँ हांगकांग में एक वित्त कर्मचारी ने यह मानकर $25 मिलियन का भुगतान किया कि वेब मीटिंग में CFO का डीपफेक संस्करण वास्तव में असली CFO था। यह उन एजेंटों के बढ़ते जोखिम को उजागर करता है जो मनुष्यों की नकल कर सकते हैं, खासकर जब से नवीनतम मल्टी-मोडल मॉडल के साथ मनुष्यों की नकल करना आसान हो गया है। OpenAI ने हाल ही में चेतावनी दी थी कि 15 सेकंड का वॉयस सैंपल किसी इंसान की आवाज़ की नकल करने के लिए पर्याप्त होगा। डीपफेक वीडियो भी बहुत पीछे नहीं हैं, जैसा कि हांगकांग के मामले से पता चलता है।
इसके अतिरिक्त, कुछ मामलों में, किसी कार्य को पूरा करने के लिए मनुष्यों और एजेंटों के बीच गुप्त-साझाकरण आवश्यक है, उदाहरण के लिए, वॉलेट के माध्यम से (व्यक्तिगत एजेंट के लिए)। उद्यम संदर्भ में, एक वित्तीय एजेंट को मनुष्यों और उनके संबंधों की कानूनी पहचान को सत्यापित करने की आवश्यकता हो सकती है। आज एजेंटों के लिए ऐसा करने का कोई मानकीकृत तरीका नहीं है। इसके बिना, एजेंट ऐसी दुनिया में मनुष्यों के साथ सहयोग करने में सक्षम नहीं होंगे जहाँ मनुष्य तेजी से सह-पायलट बनेंगे।
यह समस्या तब और भी खतरनाक हो जाती है जब AI ऑटोपायलट अनजाने में किसी मानव सहयोगी का रूप धारण करने वाले बुरे अभिनेताओं के आधार पर निर्णय ले लेते हैं। मनुष्यों को डिजिटल रूप से प्रमाणित करने के स्पष्ट तरीके के बिना, एजेंट ऐसे तरीके से कार्य करने के लिए अतिसंवेदनशील होते हैं जो सुरक्षा, अनुपालन या नैतिक विचारों जैसे व्यापक व्यावसायिक लक्ष्यों के साथ संघर्ष करते हैं।
शमन सुझाव : AI ऑटोपायलट कार्य निष्पादन में शामिल उपयोगकर्ता और एजेंट पहचान की नियमित समीक्षा आवश्यक है। संगठनों को यह सुनिश्चित करने के लिए अनुकूली एल्गोरिदम और वास्तविक समय प्रतिक्रिया तंत्र का उपयोग करना चाहिए कि AI सिस्टम बदलते उपयोगकर्ताओं और नियामक आवश्यकताओं के साथ संरेखित रहें। आवश्यकतानुसार उद्देश्यों को समायोजित करके, व्यवसाय गलत लक्ष्यों को अनपेक्षित परिणामों की ओर ले जाने से रोक सकते हैं।
AI ऑटोपायलट को सुरक्षित करना: सर्वोत्तम अभ्यास
पिछली दो परतों में चर्चित सुरक्षा नियंत्रणों के अतिरिक्त, जिनमें एलएलएम के लिए एलएलएम सुरक्षा और सह-पायलटों के लिए डेटा नियंत्रण शामिल हैं, एजेन्टिक परत के लिए पहचान और पहुंच प्रबंधन (आईएएम) के साथ-साथ विश्वसनीय कार्य निष्पादन के लिए विस्तारित भूमिका की शुरूआत आवश्यक है।
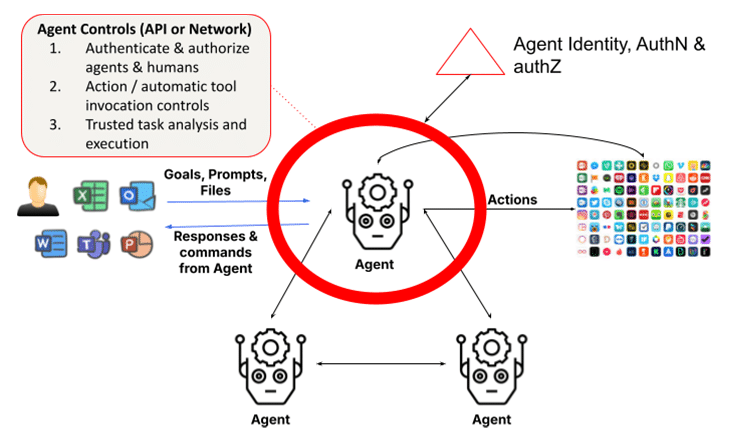
AI ऑटोपायलट के जोखिमों को कम करने के लिए, संगठनों को एक व्यापक सुरक्षा रणनीति अपनानी चाहिए। इसमें शामिल हैं:
- सतत निगरानी: विसंगतियों और अनधिकृत कार्यों का पता लगाने के लिए वास्तविक समय व्यवहार विश्लेषण को लागू करें।
- नैतिक शासन: यह सुनिश्चित करने के लिए कि AI प्रणालियाँ संगठनात्मक मूल्यों और कानूनी आवश्यकताओं के अनुरूप हों, नैतिक बोर्ड और जवाबदेही ढाँचे की स्थापना करें।
- प्रतिकूल बचाव: हेरफेर को रोकने के लिए प्रतिकूल प्रशिक्षण और मजबूत इनपुट सत्यापन का उपयोग करें।
- मानवीय निगरानी: AI द्वारा लिए गए महत्वपूर्ण निर्णयों की निगरानी बनाए रखने के लिए HITL प्रणालियों को बनाए रखें।
इन सर्वोत्तम प्रथाओं को लागू करके, संगठन यह सुनिश्चित कर सकते हैं कि AI ऑटोपायलट सुरक्षित रूप से और उनके व्यावसायिक लक्ष्यों के अनुरूप काम करें।
आगे का रास्ता: स्वायत्त एआई को सुरक्षित करना
AI ऑटोपायलट जटिल कार्यों को स्वचालित करके उद्योगों में क्रांति लाने का वादा करते हैं, लेकिन वे महत्वपूर्ण सुरक्षा जोखिम भी पेश करते हैं। दुष्ट कार्रवाइयों से लेकर प्रतिकूल हेरफेर तक, संगठनों को इन जोखिमों के प्रबंधन में सतर्क रहना चाहिए। जैसे-जैसे AI विकसित होता जा रहा है, यह सुनिश्चित करने के लिए हर चरण में सुरक्षा को प्राथमिकता देना महत्वपूर्ण है कि ये सिस्टम सुरक्षित रूप से और संगठनात्मक लक्ष्यों के अनुरूप काम करें।
अपने AI अनुप्रयोगों को सुरक्षित करने के बारे में अधिक जानने के लिए: हमारा समाधान संक्षिप्त पढ़ें
इस श्रृंखला के अन्य ब्लॉग:
- भाग 1 – एआई सुरक्षा: ग्राहकों की ज़रूरतें और अवसर
- भाग 2 – आधारभूत AI: सुरक्षा चुनौतियों के साथ एक महत्वपूर्ण परत
- भाग 3 – AI सह-पायलटों के साथ सुरक्षा जोखिम और चुनौतियाँ
- भाग 4 – एआई ऑटोपायलट के लाभ और जोखिम का मूल्यांकन
संबंधित सामग्री



ट्रेंडिंग ब्लॉग
Product Updates Q2 2026: Simplified Security Across Web, Cloud, Data, and AI
Thyaga Vasudevan July 21, 2026
Modernizing Your Symantec Edge Secure Web Gateway With Skyhigh Hybrid SSE Mesh
Sarang Warudkar July 15, 2026
Skyhigh Security CSA STAR लेवल 2 सर्टिफिकेशन प्राप्त किया, जिससे स्वतंत्र क्लाउड सुरक्षा आश्वासन के लिए मानक ऊंचा हुआ।
स्टुअर्ट बेलिस और सारंग वरुडकर 25 जून, 2026
एक अलग दृष्टिकोण: ब्राउज़र सुरक्षा का समाधान नया ब्राउज़र क्यों नहीं है?
सारंग वारुडकर 17 जून, 2026
Skyhigh Security 2026 के लिए IRAP मूल्यांकन को संरक्षित स्तर पर नवीनीकृत किया गया
सारंग वरुडकर और स्टुअर्ट बेलिस 21 मई, 2026